
KV-Cache, Q-Cache ve İleri Seviye Çıkarım Optimizasyonları Üzerine Kapsamlı Bir İnceleme
Bölüm 1: Giriş ve Hesaplamalı Dilbilimin Yeni Sınırları
Bilgisayar bilimlerinin, özellikle de doğal dil işleme (NLP) alanının son on yılda geçirdiği evrim, sadece algoritmik bir başarı hikayesi değil, aynı zamanda donanım mimarileri ile yazılım paradigmasının amansız bir dansıdır. Bir bilgisayar bilimci olarak, Büyük Dil Modellerinin (Large Language Models – LLM) başarısını incelerken, genellikle parametre sayılarına (7 milyar, 70 milyar, 1 trilyon gibi) odaklanılır. Ancak, bir modelin eğitilmesi (training) ile onun gerçek dünyada hizmet vermesi, yani çıkarım (inference) süreci, birbirinden tamamen farklı mühendislik disiplinleri gerektirir. Eğitim süreci, devasa veri kümelerinin paralel işlenmesine dayalı bir “throughput” (iş hacmi) problemiyken; çıkarım süreci, kullanıcı deneyimini doğrudan etkileyen ve milisaniyelerin hesabının yapıldığı bir “latency” (gecikme) ve bellek yönetimi (memory management) problemidir.
Bu yazının temel amacı, LLM’lerin çıkarım süreçlerinde karşılaşılan en büyük darboğaz olan “bellek duvarını” (memory wall) aşmak için geliştirilen kritik önbellekleme (caching) mekanizmalarını derinlemesine analiz etmektir. Literatürde sıkça duyduğumuz KV-Cache (Key-Value Cache), son dönemde akademik çalışmalarda öne çıkan Q-Cache (Query Cache) varyasyonları ve PagedAttention gibi mimari yenilikler, sadece basit birer hızlandırma aracı değil, modern yapay zekanın “kısa süreli belleğini” (working memory) oluşturan temel yapı taşlarıdır. Bu teknolojileri anlamak için, öncelikle terminolojik zemini sağlamlaştırmalı, ardından Transformer mimarisinin matematiksel derinliklerine inmeliyiz.
Şu yazılar ilginizi çekebilir.
- Büyük Dil Modellerinin İnşası, Bilişsel Mimariler ve Sub-Sembolik Yapay Zeka
- Gelişmiş Hesaplamalı Mimariler ve Algoritmik Verimlilik: Temellerden Nöromorfik Ölçekleme Yasalarına
- Von Neumann Darboğazı, Transformer Paradigmasının Sınırları ve Uzay Havacılığı Hesaplamasının Geleceği
- Modern Hopfield Ağları ve Yoğun İlişkisel Bellek Mimarileri: Teorik Temeller, Biyolojik Yakınsamalar ve Derin Öğrenme Entegrasyonu Üzerine Kapsamlı Araştırma Raporu
- Büyük Dil Modellerinde Softmax Fonksiyonu: Temel Kavramlardan İleri Mühendisliğe
- (ReLU) Büyük Dil Modellerinde (LLM) Doğrultulmuş Doğrusal Birimler
1.1. Temel Terminoloji ve Kavramsal Çerçeve
Bu yazı boyunca kullanacağımız teknik terimlerin, özellikle bellek hiyerarşisi ve tensör operasyonları bağlamındaki anlamlarını netleştirmek, konunun anlaşılması açısından elzemdir.
Tokenizasyon ve Vektör Uzayı:
LLM’ler metinleri bizim okuduğumuz gibi kelime kelime veya harf harf algılamazlar. Metin, “Token” adı verilen daha küçük, atomik birimlere ayrıştırılır. Bir token, bir kelimenin tamamı olabileceği gibi (“elma”), bir kelimenin kökü (“gel-“) veya bir sonek (“-iyor”) de olabilir. Modern tokenizasyon algoritmaları (örneğin Byte-Pair Encoding – BPE), sık kullanılan kelimeleri tek token olarak tutarken, nadir kelimeleri parçalar. Ortalama olarak 1000 kelimelik bir İngilizce metin yaklaşık 1300 token’a denk gelirken, Türkçe gibi sondan eklemeli dillerde bu oran değişebilir. İşlemciye giren her token, aslında yüksek boyutlu (örneğin 4096 boyutlu) bir sayı vektörüdür (Embedding).
Oto-regresif (Autoregressive) Üretim:
LLM’lerin metin üretme biçimi “oto-regresif” olarak adlandırılır. Bu, modelin bir dizideki bir sonraki elemanı tahmin etmek için, o ana kadar üretilmiş olan tüm geçmiş elemanları girdi olarak kullanması prensibine dayanır. Matematiksel olarak, $t$ anındaki bir tokenın olasılığı $P(w_t | w_{1}, w_{2},…, w_{t-1})$ şeklinde, geçmiş tüm $t-1$ tokena bağlıdır. Bu özellik, çıkarım sürecinin doğasını belirler: Seri, ardışık ve geçmişe bağımlı. Bu bağımlılık, bellek yönetimini zorlaştıran ana faktördür.
Tensörler ve Matris Çarpımları (GEMM):
Derin öğrenmenin kalbinde, General Matrix Multiply (GEMM) operasyonları yatar. Bir LLM’in çıkarım yapması, milyarlarca ağırlık parametresinin (Weights), aktivasyon vektörleriyle (Activations) çarpılması demektir. Bellek optimizasyonu konuştuğumuzda, aslında bu devasa matrislerin GPU belleğinde (VRAM) nasıl saklandığını, işlemci çekirdeklerine (CUDA Cores) ne kadar hızlı taşındığını ve işlem sonrası oluşan ara değerlerin (Intermediate States) nerede tutulduğunu tartışıyoruz demektir.
1.2. Transformer Mimarisi ve Dikkat (Attention) Mekanizması
KV-Cache’in varlık sebebini kavramak için, Transformer mimarisinin çekirdeği olan “Scaled Dot-Product Attention” mekanizmasını en ince matematiksel detayına kadar irdelememiz gerekir. Google araştırmacıları tarafından 2017 yılında “Attention Is All You Need” makalesiyle tanıtılan bu yapı, Recurrent Neural Networks (RNN) ve LSTM gibi önceki mimarilerin aksine, veriyi paralel işlemeye daha uygundur, ancak çıkarım sırasında kendine has bir bellek yükü getirir.
Bir Transformer katmanı, girdi olarak aldığı her token vektörünü ($x$), üç farklı doğrusal projeksiyon (Linear Projection) katmanından geçirerek üç yeni vektöre dönüştürür:
- Query (Sorgu – $Q$): $Q = x \cdot W_Q$
- Key (Anahtar – $K$): $K = x \cdot W_K$
- Value (Değer – $V$): $V = x \cdot W_V$
Burada $W_Q$, $W_K$ ve $W_V$, modelin eğitimi sırasında öğrenilen ağırlık matrisleridir. Bu üç bileşeni bir kütüphane analojisiyle açıklayabiliriz:
- Query ($Q$): Kütüphaneye giren bir araştırmacının (o an işlenen token) elindeki konu başlığıdır. “Ben kuantum fiziği hakkında bilgi arıyorum” der.
- Key ($K$): Kütüphanedeki kitapların (geçmişteki tüm tokenlar) sırtındaki etiketlerdir. Kitabın içeriğini özetleyen, indekslenmesini sağlayan anahtardır.
- Value ($V$): Kitabın içindeki asıl bilgidir. Eğer araştırmacının sorgusu ile kitabın etiketi uyuşursa, araştırmacı bu bilgiyi alır.
Dikkat mekanizması, bu eşleşmeyi matematiksel olarak şu formülle gerçekleştirir:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
Bu formülün çıkarım sırasındaki adım adım işleyişi şöyledir:
- Benzerlik Hesaplama ($QK^T$): O anki sorgu ($Q$), hafızadaki tüm anahtarların transpozu ($K^T$) ile çarpılır (Dot Product). Bu işlem, iki vektör arasındaki açıyı, yani anlamsal benzerliği ölçer. Sonuçta bir “Skor Matrisi” elde edilir.
- Ölçekleme ve Normalizasyon (Softmax): Skorlar, kararlı türevler için boyutun kareköküne ($\sqrt{d_k}$) bölünür ve Softmax fonksiyonundan geçirilir. Softmax, skorları 0 ile 1 arasında, toplamı 1 olan bir olasılık dağılımına dönüştürür. Bu, “Hangi geçmiş kelimeye ne kadar odaklanmalıyım?” sorusunun cevabıdır.
- Bilgi Toplama ($\times V$): Elde edilen olasılık ağırlıkları, ilgili Değer ($V$) vektörleri ile çarpılarak toplanır. Böylece, o anki token için en alakalı bilgiler geçmişten çekilmiş olur.
1.3. Çıkarım Sürecindeki Hesaplamalı Yük ve KV-Cache İhtiyacı
Standart bir Transformer modelinde, yukarıdaki işlem eğitim sırasında tüm tokenlar için aynı anda (paralel) yapılabilir çünkü tüm cümle elimizdedir. Ancak çıkarım (inference) sırasında, kelimeler tek tek üretilir. Bu durum, “Recomputation” (Yeniden Hesaplama) adı verilen devasa bir israfa yol açar.
Basit bir örnek düşünelim. Modelimiz “Yapay zeka geleceği şekillendiriyor” cümlesini üretiyor olsun.
- Adım 1: Girdi: “Yapay”. Model “Yapay” için $Q, K, V$ hesaplar. Dikkat mekanizması kendi kendine bakar. Çıktı: “zeka”.
- Adım 2: Girdi: “Yapay zeka”. Modelin yeni token “zeka”yı üretmesi için hem “Yapay” hem de “zeka” tokenlarının ilişkisine bakması gerekir. Standart yöntemde model, “Yapay” tokenı için $Q, K, V$ değerlerini yeniden hesaplar. Ayrıca “zeka” için hesaplar. Çıktı: “geleceği”.
- Adım 3: Girdi: “Yapay zeka geleceği”. Model “Yapay” ve “zeka” için işlemleri tekrar yapar. “geleceği” için sıfırdan yapar.
Bu senaryoda, $N$ uzunluğunda bir dizi üretmek için yapılan işlem sayısı $1 + 2 + 3 +… + N = \frac{N(N+1)}{2}$ yani $O(N^2)$ mertebesindedir.1 1000 kelimelik bir metin için yaklaşık 500.000 işlem birimi gerekirken, 10.000 kelimelik bir metin için bu sayı 50.000.000’a çıkar. Bu karesel artış, modelin yanıt verme süresini (latency) kabul edilemez seviyelere çeker.
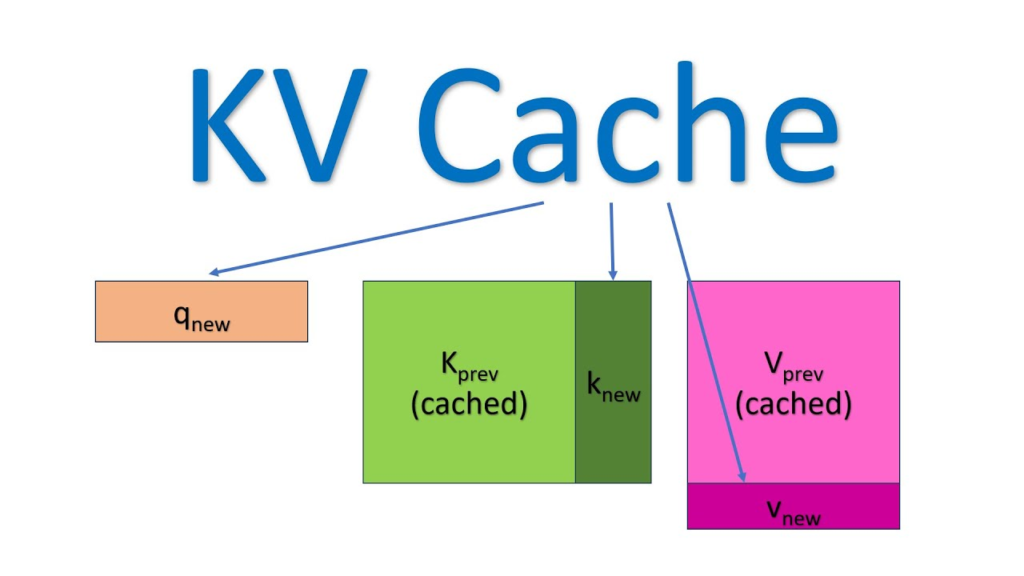
İşte bu noktada KV-Cache devreye girer. KV-Cache, hesaplamalı bir “deja-vu” yaratma sanatıdır: “Ben bu ‘Yapay’ kelimesinin Key ve Value vektörlerini az önce hesaplamıştım, neden tekrar hesaplayayım? Bunları bir kenara yazayım.”
Bölüm 2: KV-Cache: Paradigma Değişimi ve Matematiksel Analiz
KV-Cache (Anahtar-Değer Önbelleği), LLM çıkarım motorlarının (inference engines) standart bileşeni haline gelmiş bir optimizasyon tekniğidir. Temel prensibi, Transformer katmanlarında geçmiş tokenlar için hesaplanan Key ($K$) ve Value ($V$) matrislerini GPU belleğinde saklamak ve her yeni adımda sadece yeni gelen token için işlem yapmaktır. Bu teknik, çıkarım sürecindeki $O(N^2)$ hesaplama karmaşıklığını, her adım için $O(N)$ (veya toplam süreç için bellek erişimi dahil edildiğinde lineer artış) seviyesine indirir.
2.1. KV-Cache Çalışma Mekanizması: Adım Adım İzleme
KV-Cache devredeyken süreç şu şekilde işler:
- Prefill (Ön Dolum) Aşaması: Kullanıcının girdiği “prompt” (örneğin 50 kelimelik bir soru), modele bir bütün olarak verilir. Bu aşamada paralelleştirme mümkündür. Model, bu 50 tokenın tamamı için $K$ ve $V$ matrislerini hesaplar. Bu matrisler, GPU belleğinde ayrılan özel bir alana (Cache) yazılır. Bu aşama genellikle “Compute Bound” (İşlem Gücü Sınırlı) bir süreçtir çünkü GPU çekirdekleri yoğun matris çarpımları yapar.
- Decoding (Kod Çözme) Aşaması: Model 51. kelimeyi üretecektir.
- Sadece 51. kelimenin (yeni token) $Q_{51}, K_{51}, V_{51}$ vektörleri hesaplanır.
- Dikkat işlemi için, $Q_{51}$ vektörü, Cache’ten okunan geçmiş 50 tokenın $K_{1:50}$ vektörleri ve yeni hesaplanan $K_{51}$ ile çarpılır.
- Sonuçta elde edilen dikkat skorları, Cache’ten okunan $V_{1:50}$ ve yeni $V_{51}$ ile ağırlıklandırılır.
- Son olarak, yeni hesaplanan $K_{51}$ ve $V_{51}$, Cache’in sonuna eklenir (Append).
- Döngü: 52. kelime üretilirken, Cache’te artık 51 eleman vardır. Süreç tekrarlanır.
Bu yöntemle, her adımda matris çarpımı boyutu, geçmişin uzunluğu ne olursa olsun, sadece “1 token x Geçmiş Boyutu” şeklindedir. Geçmiş tokenların $K$ ve $V$ projeksiyonları (Linear Layers) tekrar hesaplanmaz. Bu, FLOPS (Saniye Başına Kayan Nokta İşlemi) açısından muazzam bir tasarruftur.3 Örneğin, 40 saniye sürecek bir işlem, KV-Cache ile 9 saniyeye düşebilir (~4.5 kat hızlanma).
2.2. Neden Q-Cache (Sorgu Önbelleği) Yoktur? (Klasik Mimaride)
Bu noktada sıkça sorulan ve kavramsal karmaşaya yol açan bir soru şudur: “Neden K ve V saklanıyor da Q (Query) saklanmıyor? Neden KQV-Cache değil?”
Bunun cevabı, dikkat mekanizmasının yönlü doğasında yatar. Dikkat, “Şimdiki zamanın geçmişe bakmasıdır”.
- Geçmiş ($K, V$): Geçmişte üretilen kelimelerin kimlikleri ($K$) ve içerikleri ($V$) sabittir. “Yapay” kelimesi üretildikten 100 adım sonra da “Yapay” kelimesi olarak kalır ve içeriği değişmez. Bu yüzden saklanabilirler.
- Şimdi ($Q$): Her adımda “şimdi” değişir. 51. adımda sorgu yapan vektör $Q_{51}$’dir. 52. adımda sorgu yapan vektör $Q_{52}$ olacaktır. $Q_{51}$ vektörü, 52. adımda üretilen token ile bir ilişkiye girmez (Causal Masking nedeniyle gelecek geçmişi görmez, geçmiş de geleceği sorgulamaz). Dolayısıyla, eski $Q$ vektörlerinin gelecekteki hesaplamalarda bir kullanım alanı yoktur.4
Ancak, yazının ilerleyen bölümlerinde (Bölüm 4) göreceğimiz üzere, “Lookahead” gibi özel algoritmalar bu kuralı esneterek “Q-Cache” kavramını literatüre sokmuştur.
2.3. KV-Cache’in Bedeli: Bellek Kapasitesi ve Bant Genişliği Analizi
KV-Cache, işlem gücünden (Compute) tasarruf etmek için bellekten (Memory) harcama stratejisidir. Ancak modern LLM’lerde bu harcama o kadar büyüktür ki, yeni bir darboğaz yaratmıştır. Buna literatürde “Memory Wall” (Bellek Duvarı) denir.
Bellek Boyutu Formülü:
Bir modelin KV-Cache için ne kadar belleğe ihtiyaç duyduğunu hesaplamak için şu formülü kullanırız 2:
$$M_{KV} = 2 \times n_{\text{layers}} \times n_{\text{heads}} \times d_{\text{head}} \times n_{\text{seq}} \times P_{\text{byte}} \times B_{\text{size}}$$
Değişkenlerin açıklaması ve birim analizi:
- 2: Hem Key ($K$) hem Value ($V$) matrisleri saklandığı için.
- $n_{\text{layers}}$: Modeldeki katman sayısı (Örn: GPT-3-175B için 96 katman).
- $n_{\text{heads}}$: Katman başına dikkat başlığı sayısı (Örn: 96 başlık).
- $d_{\text{head}}$: Her başlığın vektör boyutu (Örn: 128). Genellikle $d_{\text{model}} / n_{\text{heads}}$’tir.
- $n_{\text{seq}}$: Bağlam uzunluğu (Sequence Length). Yani prompt + üretilen token sayısı.
- $P_{\text{byte}}$: Veri hassasiyeti (Precision). FP16 (Yarım Hassasiyet) için 2 bayt, FP32 için 4 bayt.
- $B_{\text{size}}$: Batch Size (Aynı anda hizmet verilen kullanıcı sayısı).
Örnek Senaryo: Llama-3-70B Analizi
Meta’nın Llama-3 70B modelini ele alalım. Yaklaşık parametreler:
- $n_{\text{layers}} \approx 80$
- $n_{\text{heads}} \approx 64$
- $d_{\text{head}} \approx 128$
- Precision: FP16 (2 Byte)
Tek bir token için gereken KV-Cache alanı:
$2 \times 80 \times 64 \times 128 \times 2 \approx 2,621,440$ bayt $\approx 2.5$ MB.
Bu sayı ilk bakışta küçük görünebilir. Ancak:
- Uzun Bağlam (Long Context): Eğer model 128.000 (128k) tokenlık bir bağlam penceresiyle çalışıyorsa (bir kitap özeti gibi), tek bir kullanıcı için:
$128,000 \times 2.5 \text{ MB} \approx 320 \text{ GB}$
Bu miktar, piyasadaki en güçlü GPU olan NVIDIA H100’ün (80GB) belleğinin 4 katıdır! Sadece bir kullanıcının önbelleği için 4 adet H100 GPU gerekir. - Batch Size (Eşzamanlılık): Bir sunucunun aynı anda 10 kişiye hizmet vermesi gerekiyorsa, bu bellek ihtiyacı lineer olarak artar.
Bellek Bant Genişliği (Memory Bandwidth) Darboğazı:
Sorun sadece depolama kapasitesi (GB) değil, aynı zamanda veri transfer hızıdır (GB/s). Decoding aşamasında, her yeni token üretimi için GPU, bellekteki bu devasa KV-Cache yığınını okumak zorundadır.
NVIDIA A100 GPU’nun bellek bant genişliği yaklaşık 2 TB/s’dir (Terabayt/saniye). Eğer cache boyutumuz 20 GB ise, teorik olarak saniyede en fazla 100 token üretebiliriz (2000 / 20 = 100). Modelin hesaplama gücü (FLOPS) ne kadar yüksek olursa olsun, veriyi bellekten getirip çekirdeğe sokamadığınız sürece hızlanamazsınız. Buna “Memory Bound” (Bellek Sınırlı) durum denir.5
Aşağıdaki tablo, bellek darboğazının farklı donanımlardaki etkisini özetlemektedir:
| Donanım | Bellek (HBM) | Bant Genişliği | Tipik LLM Çıkarım Durumu |
| NVIDIA A100 | 40GB / 80GB | 1.6 – 2.0 TB/s | Düşük batch boyutlarında Bellek Sınırlı (Memory Bound) |
| NVIDIA H100 | 80GB | 3.35 TB/s | Bant genişliği artışı sayesinde daha yüksek throughput, ancak hala sınırlı |
| Tüketici GPU (RTX 4090) | 24GB (GDDR6X) | 1.0 TB/s | Büyük modeller için yetersiz kapasite, yoğun offloading gerekir |
Bölüm 3: Bellek Yönetiminde Devrim: PagedAttention ve vLLM
KV-Cache’in yarattığı devasa bellek yükü, klasik bellek yönetim tekniklerinin (allocation strategies) yetersiz kalmasına neden olmuştur. Geleneksel derin öğrenme kütüphaneleri (PyTorch gibi), tensörler için bellekte “bitişik” (contiguous) alanlar ayırır. Örneğin, bir kullanıcıya “maksimum 2048 token üretebilir” diyerek, 2048’lik bir yer peşinen rezerve edilir. Ancak kullanıcı sadece 50 token üretip sohbeti bitirirse, kalan 1998’lik alan başka kimse tarafından kullanılamaz. Buna Bellek Parçalanması (Fragmentation) denir. Yapılan araştırmalar, geleneksel sistemlerde belleğin %60 ila %80’inin bu şekilde israf edildiğini göstermiştir.
3.1. İşletim Sistemlerinden İlham: Sanal Bellek ve Sayfalama
Bilgisayar bilimlerinde, karmaşık bir sorunla karşılaşıldığında genellikle tarihe bakmak faydalıdır. 1960’larda ve 70’lerde bilgisayarlar benzer bir RAM sorunu yaşıyordu. İşletim Sistemleri (OS) bu sorunu Sanal Bellek (Virtual Memory) ve Sayfalama (Paging) ile çözdü. Programlara fiziksel RAM adresleri yerine sanal adresler verilir ve bu adresler küçük “sayfalar” (pages) halinde fiziksel belleğe dağıtılır.
Berkeley Üniversitesi araştırmacıları (daha sonra vLLM ekibi), bu konsepti LLM dünyasına PagedAttention adıyla taşıdılar.8
3.2. PagedAttention Mekanizması
PagedAttention algoritması, KV-Cache’i bitişik bir blok yerine, küçük ve sabit boyutlu bloklara (örneğin her blok 16 token) böler.
- Mantıksal Bloklar: Tokenlar mantıksal olarak birbirini takip eder (Sıralı).
- Fiziksel Bloklar: GPU belleğinde (VRAM) bu bloklar rastgele yerlerde saklanabilir.
- Blok Tablosu (Block Table): İşletim sistemindeki sayfa tablosu (page table) gibi, hangi mantıksal bloğun hangi fiziksel adreste olduğunu tutan bir harita kullanılır.
Çalışma Prensibi:
- Kullanıcı bir istek gönderdiğinde, sistem sadece ihtiyaç duyulan kadar blok (örneğin ilk 16 token için 1 blok) ayırır.
- Token sayısı arttıkça, yeni bloklar dinamik olarak tahsis edilir. Bu blokların fiziksel bellekte yan yana olması gerekmez.
- Dikkat (Attention) hesaplaması sırasında, özel olarak yazılmış CUDA çekirdekleri (Kernels), Blok Tablosuna bakarak gerekli verileri dağınık adreslerden toplar ve işlemi yapar.
Bu yaklaşım, Dışsal Parçalanmayı (External Fragmentation) tamamen ortadan kaldırır. Çünkü bellekteki herhangi bir boş blok, herhangi bir kullanıcı için kullanılabilir. Sadece son blok tam dolmadığında çok küçük bir İçsel Parçalanma (Internal Fragmentation) oluşur, bu da ihmal edilebilir düzeydedir. Sonuç olarak, vLLM kütüphanesi ile aynı GPU üzerinde 2 ila 4 kat daha fazla kullanıcıya (Throughput) hizmet verilebilir.9
3.3. Paylaşımlı Önekler (Prefix Sharing) ve Copy-on-Write
PagedAttention’ın bir diğer devrimsel özelliği, bellek paylaşımına izin vermesidir.
Örneğin, bir sistemde 100 kullanıcıya hizmet veriliyor ve hepsine aynı “Sistem Komutu” (System Prompt) gönderiliyor: “Sen yardımcı bir asistansın. Lütfen nazik ol…” (diyelim ki 50 token).
Klasik yöntemde bu 50 tokenın KV-Cache’i her kullanıcı için ayrı ayrı saklanır (100 kopya).
PagedAttention ile, bu 50 tokenlık kısım fiziksel bellekte sadece bir kez saklanır. Tüm kullanıcıların Blok Tabloları, bu fiziksel adrese işaret eder.
Eğer bir kullanıcı bu ortak kısmı değiştirmeye çalışırsa (ki LLM’lerde geçmiş değişmez ama dallanma olabilir), sistem o bloğun bir kopyasını oluşturur (Copy-on-Write).
Bu özellik, “Parallel Sampling” (Bir soruya 3 farklı cevap üret) veya “Beam Search” gibi gelişmiş algoritmaların bellek maliyetini radikal biçimde düşürür.
Bölüm 4: Q-Cache ve Yeni Nesil Tahliye (Eviction) Stratejileri
Yazının bu bölümünde, kullanıcının özellikle vurguladığı ve literatürde daha yeni yer bulan Q-Cache (Sorgu Önbelleği) kavramını ve bununla ilişkili ileri seviye teknikleri inceleyeceğiz. Bölüm 2.2’de standart mimaride Q-Cache’in olmadığını belirtmiştik. Ancak, “Sonsuz Bağlam” (Infinite Context) ve RAG sistemleri gibi uç senaryolar, bu paradigmayı değiştiren yeni yaklaşımlar doğurmuştur.
4.1. Yanılgıları Gidermek: Q-Cache Nedir, Ne Değildir?
İnternet forumlarında (örneğin Reddit veya GitHub tartışmalarında) “Q-Cache” terimi bazen yanlışlıkla “Quantized Cache” (Kuantize Edilmiş Cache) anlamında kullanılmaktadır.11 Kuantizasyon (Bölüm 5’te değineceğiz), verinin bit sayısını düşürmektir (örneğin 16-bit’ten 4-bit’e). Ancak akademik literatürde “Q-Cache” denildiğinde, özellikle 2024-2025 dönemindeki makalelerde, Sorgu Vektörlerinin Stratejik Saklanması kastedilmektedir.
Burada iki ana yaklaşım öne çıkar:
- Lookahead Q-Cache (LAQ): Tahliye (Eviction) kararlarını iyileştirmek için kullanılan geçici sorgu tamponu.
- Contextual Q-Cache: RAG sistemlerinde dökümanlar arası ilişkiyi kuran zenginleştirilmiş sorgu deposu.
4.2. Lookahead Q-Cache (LAQ): Geleceğe Bakarak Karar Vermek
LLM’lerin bağlam uzunluğu sınırlıdır (GPU belleği nedeniyle). Metin çok uzadığında, KV-Cache’ten bazı eski tokenları silmemiz (Eviction) gerekir.
- Klasik Yöntemler (H2O, StreamingLLM): “Geçmişte bu kelimeye ne kadar dikkat edildi?” sorusunu sorar. Eğer “Yapay” kelimesine az bakılmışsa, onu siler.
- Sorun (Tahliye Tutarsızlığı): Bir kelime geçmişte önemsiz olabilir, ama gelecekte (henüz üretilmemiş bir cümlede) hayati önem taşıyabilir. Geçmiş veriye dayanarak silmek, gelecekteki performansı düşürür.13
Lookahead Q-Cache Çözümü:
EMNLP 2025’te sunulan bu yöntem, modelin “geleceği görmesini” sağlar. Mekanizma şöyledir:
- Sözde-Sorgu (Pseudo-Query) Üretimi: Model, gerçek cevabı üretmeden önce, çok düşük maliyetli bir şekilde (örneğin daha küçük bir taslak modelle veya düşük hassasiyetle) gelecekte üretilmesi muhtemel birkaç tokenı (örneğin sonraki 8 token) tahmin eder.
- Q-Cache Oluşumu: Bu tahmin edilen gelecek tokenların Query vektörleri hesaplanır ve Q-Cache adı verilen geçici bir alanda saklanır.
- Gelecek Odaklı Tahliye: Sistem, KV-Cache’ten hangi tokenı sileceğine karar verirken şunu sorar: “Bu token, Q-Cache’teki (gelecekteki) sorgularla eşleşiyor mu?”
- Eğer eşleşiyorsa (yani gelecekte lazım olacaksa), geçmişte hiç kullanılmamış olsa bile silinmez.
- Eğer ne geçmişte ne de gelecekte (Q-Cache’te) işe yaramıyorsa, güvenle silinir.
Bu yöntem, özellikle uzun döküman özetleme veya “Needle-in-a-Haystack” (Samanlıkta İğne Arama) testlerinde, modelin kritik bilgileri unutmasını engeller. Q-Cache burada kalıcı bir depo değil, dinamik bir karar destek mekanizmasıdır.14
4.3. Contextual Q-Cache ve RAG Sistemleri
Bilgi Erişim (Retrieval Augmented Generation – RAG) sistemlerinde, kullanıcı sorusu ($Q$), binlerce dökümanla karşılaştırılır. Standart sistemde sorgu statiktir.
Ancak Contextual Q-Cache yaklaşımında 17, sorgu vektörü her bir dökümanın içeriğine göre hafifçe modifiye edilerek zenginleştirilir.
- Initial Q-Cache: Sorgunun ham hali.
- Local Q-Cache: Belirli bir dökümanla etkileşime girdikten sonra oluşan, o dökümana özgü bağlamı içeren hali.
Bu zenginleştirilmiş sorgular önbelleğe alınır. Böylece, benzer dökümanlar tarandığında model tekrar tekrar bağlam oluşturmak zorunda kalmaz. Bu, özellikle çoklu döküman (Multi-hop QA) sorularında doğruluğu artırır.
4.4. Diğer Önbellekleme ve Tahliye Stratejileri
KV-Cache’in dolması durumunda kullanılan diğer popüler stratejiler şunlardır:
- Sliding Window (Kayan Pencere): Sadece son $N$ token saklanır (örneğin 4096). Mistral 7B modeli bu mimariyi kullanır. Dikkat mekanizması sadece bu pencereye bakar. Eski bilgiler tamamen kaybolur. Bellek kullanımı sabittir ($O(1)$), ancak uzun süreli hafıza yoktur.18
- Rolling Buffer: Bu pencerenin bellekte kaydırılma yöntemidir. Veriler fiziksel olarak kopyalanmaz, dairesel bir tampon (circular buffer) kullanılır.
- Attention Sinks (StreamingLLM): Araştırmacılar ilginç bir fenomen keşfettiler: Modelin dikkatinin bozulmaması için ilk birkaç tokenın (başlangıç tokenları) mutlaka saklanması gerekir. Bunlara “Attention Sink” (Dikkat Lavabosu) denir. Eğer ilk tokenları silerseniz, model çöker. StreamingLLM, ilk 4 tokenı ve son 1000 tokenı saklayıp, aradakileri silerek sonsuz uzunlukta akıcı konuşma sağlar.
- H2O (Heavy Hitter Oracle): Her tokenın kümülatif dikkat skorunu takip eder. En çok “bakılan” tokenları (Heavy Hitters) saklar, az bakılanları atar.
Bölüm 5: Mimari Optimizasyonlar: MQA, GQA ve Kuantizasyon
Yazılımsal hilelerin (PagedAttention, Tahliye) ötesinde, modelin mimarisini ve veri tipini değiştirerek de bellek tasarrufu sağlanabilir.
5.1. Multi-Query (MQA) ve Grouped-Query Attention (GQA)
Standart Transformer (Multi-Head Attention – MHA) yapısında, her Query başlığı için ayrı bir Key ve Value başlığı vardır.
- MHA: 64 Query, 64 Key, 64 Value. (KV-Cache Boyutu: %100)
- MQA (Multi-Query Attention): Tüm Query başlıkları, tek bir Key ve Value başlığını paylaşır. 64 Query, 1 Key, 1 Value. (KV-Cache Boyutu: %1.5). Bellek kullanımı radikal düşer ancak modelin ifade gücü (kalitesi) azalabilir.20
- GQA (Grouped-Query Attention): Llama-2 ve Llama-3’ün kullandığı modern standarttır. Query başlıkları gruplara ayrılır. Örneğin 8 grup. Her grup 1 KV çifti paylaşır. 64 Query, 8 Key, 8 Value. (KV-Cache Boyutu: %12.5). Kalite MHA kadar iyidir, hız MQA kadar yüksektir.
Aşağıdaki tablo bu mimarilerin karşılaştırmasını sunar:
| Mimari | Key-Value Başlık Sayısı | Bellek Kullanımı | Kalite (Accuracy) | Örnek Model |
| MHA (Multi-Head) | $N$ (Query ile eşit) | Yüksek (%100) | En Yüksek | GPT-3, Orijinal Llama |
| GQA (Grouped-Query) | $N / G$ (Grup sayısı) | Orta (~%12-25) | Çok Yüksek (MHA’ya yakın) | Llama-3, Mistral |
| MQA (Multi-Query) | 1 | Çok Düşük (~%1-2) | Düşük/Orta | SantaCoder, Falcon (bazıları) |
5.2. Kuantizasyon: Hassasiyetten Ödün Vererek Sıkıştırma
KV-Cache’teki veriler normalde FP16 (16-bit) formatındadır. Bunu azaltmak mümkündür:
- FP8 (8-bit): NVIDIA H100 GPU’lar donanımsal FP8 desteğiyle gelir. Cache boyutu yarıya iner, kalite kaybı neredeyse yoktur.
- INT4 (4-bit): Cache boyutunu 4 kat küçültür. Ancak dikkat matrisleri “Outlier” (aşırı uç) değerlere çok duyarlıdır. 4-bit’e düşürmek modeli bozabilir.
- KIVI ve AWQ: Bu algoritmalar, matrisin “önemli” kısımlarını yüksek hassasiyette, kalanını düşük hassasiyette tutan hibrit yöntemler kullanır. Örneğin, dikkat skorlarını etkileyen büyük değerler FP16 kalır, diğerleri INT4 olur.
Bölüm 6: İleri Seviye Konular ve Gelecek Yönelimleri
6.1. Disk Offloading (NVMe Caching)
GPU belleği (HBM) çok pahalıdır ve sınırlıdır (80GB). Sistem RAM’i (DRAM) daha ucuzdur (Terabaytlarca olabilir). NVMe SSD diskler ise çok daha ucuzdur.
Bazı sistemler (örneğin DeepSpeed-Inference), KV-Cache GPU’ya sığmadığında, veriyi CPU RAM’ine veya NVMe disklere taşır (Offloading).
- Avantaj: Çok daha büyük modeller veya çok daha uzun bağlamlar tek bir GPU’da çalışabilir.
- Dezavantaj: PCIe veriyolu hızı darboğaz olur. GPU belleği 3000 GB/s iken, PCIe Gen5 sadece 128 GB/s hızındadır. Bu yüzden bu yöntem “Interactive” (sohbet) sistemler için değil, “Offline” (toplu işlem) sistemler için uygundur.21
6.2. Semantic Caching (Anlamsal Önbellek)
Bu yazının odak noktası olan “Model İçi Cache”lerden farklı olarak, Semantic Cache modelin dışında çalışır.
Kullanıcı “Nasıl kilo veririm?” diye sorduğunda, model cevap üretir ve bu çift (Soru-Cevap) bir vektör veritabanına kaydedilir.
Başka bir kullanıcı “Zayıflama yöntemleri nelerdir?” diye sorduğunda, sistem bu sorunun vektörünü (embedding) alır, veritabanında arar. Anlamsal olarak %95 benzerlik bulursa, modeli hiç çalıştırmadan eski cevabı döndürür.23
Bu, maliyeti ve gecikmeyi sıfıra indiren en etkili yöntemdir, ancak dinamik/kişisel sorularda (örneğin “Şu an saat kaç?”) kullanılamaz.
6.3. Prefill-Decode Ayrıştırması (Disaggregation)
Modern veri merkezlerinde, Prefill (ilk okuma) ve Decode (kelime üretme) işlemleri farklı karakteristikte olduğu için, bunlar farklı makinelerde yapılır.24
- Prefill Makineleri: Hesaplama gücü yüksek GPU’lar. KV-Cache’i üretir ve ağ üzerinden diğer makineye atar.
- Decode Makineleri: Bellek bant genişliği yüksek GPU’lar. Hazır KV-Cache’i alır ve token üretir.
Bu mimari, kaynak kullanımını optimize eder ancak makineler arası hızlı ağ bağlantısı (RDMA, InfiniBand) gerektirir.
Sonuç
Büyük Dil Modellerinde çıkarım süreci, basit bir matris çarpımından çok, karmaşık bir bellek ve veri lojistiği problemine dönüşmüştür. KV-Cache, bu sürecin vazgeçilmez temel taşıdır ve otoregresif üretimin maliyetini yönetilebilir kılar. PagedAttention gibi teknolojiler bu belleğin verimli kullanılmasını sağlayarak modern yapay zeka servislerinin (ChatGPT, Claude vb.) ekonomik olarak mümkün olmasını sağlamıştır.
Kullanıcının özellikle ilgilendiği Q-Cache, standart mimarinin bir parçası olmamakla birlikte, Lookahead algoritmalarıyla birlikte “geleceğe yönelik tahminleme” yaparak bellek tahliyesini optimize eden yenilikçi bir araştırma alanıdır.
Gelecekte, donanım üreticilerinin bellek kapasitesini artırma çabalarına (HBM3e, HBM4), yazılımcıların “daha az bit ile daha çok bilgi” saklama (Kuantizasyon) ve “neyin unutulacağını daha iyi seçme” (Akıllı Tahliye) algoritmaları eşlik edecektir. Bu sinerji, yapay zekanın sadece daha zeki değil, aynı zamanda daha hızlı ve erişilebilir olmasının anahtarıdır.
Alıntılanan çalışmalar
- From Theory to Practice: Demystifying the Key-Value Cache in Modern LLMs, erişim tarihi Aralık 21, 2025, https://alain-airom.medium.com/from-theory-to-practice-demystifying-the-key-value-cache-in-modern-llms-9674e9f904a5
- Transformer Inference Arithmetic | kipply’s blog, erişim tarihi Aralık 21, 2025, https://kipp.ly/transformer-inference-arithmetic/
- KV Caching in LLMs, explained visually – Daily Dose of Data Science, erişim tarihi Aralık 21, 2025, https://www.dailydoseofds.com/p/kv-caching-in-llms-explained-visually/
- What is the Transformer KV Cache? – Peter Chng, erişim tarihi Aralık 21, 2025, https://peterchng.com/blog/2024/06/11/what-is-the-transformer-kv-cache/
- Decoding Real-Time LLM Inference: A Guide to the Latency vs. Throughput Bottleneck, erişim tarihi Aralık 21, 2025, https://medium.com/learnwithnk/decoding-real-time-llm-inference-a-guide-to-the-latency-vs-throughput-bottleneck-c1ad96442d50
- Efficient LLM Inference: Bandwidth, Compute, Synchronization, and Capacity are all you need – arXiv, erişim tarihi Aralık 21, 2025, https://arxiv.org/html/2507.14397v1
- Bandwidth vs. Latency: We Chatted With an Internet Connectivity Expert to Understand the Difference – CNET, erişim tarihi Aralık 21, 2025, https://www.cnet.com/home/internet/bandwidth-vs-latency-whats-the-difference/
- Scalable Inference with RDMA and Tiered KV Caching | by Nadeem Khan(NK) | LearnWithNK | Nov, 2025, erişim tarihi Aralık 21, 2025, https://medium.com/learnwithnk/scalable-inference-with-rdma-and-tiered-kv-caching-9d7e494a863b
- LLM Inference Optimization Techniques | Clarifai Guide, erişim tarihi Aralık 21, 2025, https://www.clarifai.com/blog/llm-inference-optimization/
- Paged Attention – vLLM, erişim tarihi Aralık 21, 2025, https://docs.vllm.ai/en/latest/design/paged_attention.html
- Xnhyacinth/Awesome-LLM-Long-Context-Modeling: Must-read papers and blogs on LLM based Long Context Modeling – GitHub, erişim tarihi Aralık 21, 2025, https://github.com/Xnhyacinth/Awesome-LLM-Long-Context-Modeling
- ACL ARR 2025 May – OpenReview, erişim tarihi Aralık 21, 2025, https://openreview.net/group?id=aclweb.org/ACL/ARR/2025/May
- Lookahead Q-Cache: Achieving More Consistent KV Cache Eviction via Pseudo Query, erişim tarihi Aralık 21, 2025, https://arxiv.org/html/2505.20334v2
- Lookahead Q-Cache: Achieving More Consistent KV Cache Eviction via Pseudo Query – ACL Anthology, erişim tarihi Aralık 21, 2025, https://aclanthology.org/2025.emnlp-main.1732.pdf
- Lookahead Q-Cache: Achieving More Consistent KV Cache Eviction via Pseudo Query, erişim tarihi Aralık 21, 2025, https://arxiv.org/html/2505.20334v1
- Lookahead Q-Cache: Achieving More Consistent KV Cache Eviction via Pseudo Query – OpenReview, erişim tarihi Aralık 21, 2025, https://openreview.net/pdf?id=zcmF1uGQdc
- Sparse Attention across Multiple-context KV Cache – arXiv, erişim tarihi Aralık 21, 2025, https://arxiv.org/html/2508.11661v1
- What is Sliding Window Attention? – Klu.ai, erişim tarihi Aralık 21, 2025, https://klu.ai/glossary/sliding-window-attention
- Mastering Mistral AI: From Sliding Window Attention to Efficient Inference | by Ebad Sayed, erişim tarihi Aralık 21, 2025, https://medium.com/@sayedebad.777/mastering-mistral-ai-from-sliding-window-attention-to-efficient-inference-22d944384788
- Reducing Transformer Key-Value Cache Size with Cross-Layer Attention – arXiv, erişim tarihi Aralık 21, 2025, https://arxiv.org/html/2405.12981v1
- How to Reduce KV Cache Bottlenecks with NVIDIA Dynamo | NVIDIA Technical Blog, erişim tarihi Aralık 21, 2025, https://developer.nvidia.com/blog/how-to-reduce-kv-cache-bottlenecks-with-nvidia-dynamo/
- Choosing Google Cloud Managed Lustre for your external KV Cache, erişim tarihi Aralık 21, 2025, https://cloud.google.com/blog/products/storage-data-transfer/choosing-google-cloud-managed-lustre-for-your-external-kv-cache
- Semantic Caching: A Practical Guide to Smarter, Faster Retrieval Systems – Krishna Konar, erişim tarihi Aralık 21, 2025, https://krishnakonar12.medium.com/semantic-caching-a-practical-guide-to-smarter-faster-retrieval-systems-e98f023cb0e7
- Master KV cache aware routing with llm-d for efficient AI inference – Red Hat Developer, erişim tarihi Aralık 21, 2025, https://developers.redhat.com/articles/2025/10/07/master-kv-cache-aware-routing-llm-d-efficient-ai-inference






1 thought on “KV-Cache ve Q-Cache Nedir?”