Giriş: Sıralı İşlemeden Paralel Dikkat Paradigmasına Evrimsel Geçiş
Doğal Dil İşleme (NLP) ve genel olarak dizisel veri işleme (sequence processing), bilgisayar bilimlerinin en karmaşık problemlerinden biri olmuştur. İnsan dili, doğası gereği zamansal bir boyuta ve hiyerarşik bir yapıya sahiptir; bir kelimenin anlamı, kendisinden çok önce gelen bir kelimeye veya cümlenin genel bağlamına sıkı sıkıya bağlı olabilir. Bu “uzun vadeli bağımlılık” (long-range dependency) problemini çözmek için geliştirilen mimariler, yapay zeka tarihinin en önemli dönüm noktalarını oluşturur.
1.1. Tekrarlayan Sinir Ağları (RNN) ve Bilgi Darboğazı Sorunu
2017 öncesi dönemde, makine çevirisi ve metin üretimi gibi görevlerin standart çözümü Tekrarlayan Sinir Ağları (Recurrent Neural Networks – RNN) ve bunların daha kararlı türevleri olan Uzun Kısa Süreli Bellek (LSTM) ve Gated Recurrent Units (GRU) idi. RNN mimarisi, insan okuma sürecini taklit ederek veriyi soldan sağa, adım adım işler.
Matematiksel olarak, bir RNN hücresi $t$ anında şu işlemi gerçekleştirir:
$$h_t = f(h_{t-1}, x_t)$$
Burada $h_t$ o anki gizli durum (hidden state), $h_{t-1}$ bir önceki adımın gizli durumu ve $x_t$ o anki girdidir. Bu özyinelemeli (recursive) yapı, iki temel ve kritik sorunu beraberinde getirir:
- Sıralı İşleme Zorunluluğu (Sequential Computation Bottleneck): $h_t$’nin hesaplanabilmesi için $h_{t-1}$’in tamamlanmış olması mutlak bir zorunluluktur. Bu durum, modern GPU’ların (Graphics Processing Unit) ve TPU’ların (Tensor Processing Unit) devasa paralel işlem gücünden (SIMD – Single Instruction, Multiple Data) yararlanılmasını engeller. Dizi uzunluğu $N$ olduğunda, işlem süresi $O(N)$ karmaşıklığındadır ve bu süre donanım eklenerek azaltılamaz.1
- Bilgi Sıkışması ve Unutma (Information Bottleneck): Encoder-Decoder yapılı RNN’lerde (Sequence-to-Sequence), Encoder tüm giriş cümlesini okur ve son gizli durum olan $h_N$’i üretir. Bu vektör, “Bağlam Vektörü” (Context Vector) olarak adlandırılır ve Decoder’a iletilen tek bilgidir. Cümle ne kadar uzun olursa olsun (ister 5 kelime, ister 500 kelime), tüm anlamın bu sabit boyutlu vektöre sıkıştırılması gerekir. Bu durum, bilginin kaybolmasına (“Vanishing Gradient” problemi ile birleşerek) ve modelin cümlenin başındaki detayları unutmasına neden olur. Claude Shannon’ın bilgi teorisi perspektifinden bakıldığında, sabit bit genişliğine sahip bir kanal üzerinden sonsuz entropi aktarılmaya çalışılmaktadır ki bu teorik olarak kayıplı olmak zorundadır.2
Şu yazılar ilginizi çekebilir.
- Büyük Dil Modellerinin İnşası, Bilişsel Mimariler ve Sub-Sembolik Yapay Zeka
- Gelişmiş Hesaplamalı Mimariler ve Algoritmik Verimlilik: Temellerden Nöromorfik Ölçekleme Yasalarına
- Von Neumann Darboğazı, Transformer Paradigmasının Sınırları ve Uzay Havacılığı Hesaplamasının Geleceği
- Modern Hopfield Ağları ve Yoğun İlişkisel Bellek Mimarileri: Teorik Temeller, Biyolojik Yakınsamalar ve Derin Öğrenme Entegrasyonu Üzerine Kapsamlı Araştırma Raporu
- Büyük Dil Modellerinde Softmax Fonksiyonu: Temel Kavramlardan İleri Mühendisliğe
- (ReLU) Büyük Dil Modellerinde (LLM) Doğrultulmuş Doğrusal Birimler
- KV-Cache ve Q-Cache Nedir?
- TCP/IP Protokol Mimarisinde Nagle Algoritması
1.2. Dikkat Mekanizmasının Doğuşu: Bahdanau ve Luong Dikkati
Bu bilgi darboğazını aşmak için Dzmitry Bahdanau ve arkadaşları (2014) ile Luong ve arkadaşları (2015), sinir ağlarına “dikkat” yeteneği kazandıran devrimsel bir yaklaşım önerdiler. İnsan görsel sisteminden ve bilişsel süreçlerinden ilham alan bu mekanizma, “Kokteyl Partisi Etkisi”ne benzer bir prensiple çalışır: Gürültülü bir ortamda (tüm giriş verisi), sistem sadece odaklandığı sinyale (ilgili kelimeler) yüksek ağırlık verirken, diğer sinyalleri (gürültü) bastırır.
Bahdanau Dikkati (Additive Attention):
Bahdanau, Decoder’ın her çıktı kelimesini üretirken, Encoder’ın tüm gizli durumlarına ($h_1, h_2,…, h_N$) bakabilmesini önerdi. Ancak hepsine eşit bakmak yerine, hangisinin o anki çıktı için önemli olduğuna dinamik olarak karar veren bir “hizalama” (alignment) fonksiyonu geliştirdi. Bu fonksiyon, küçük bir ileri beslemeli sinir ağı (Feed-Forward Network) olarak uygulanır:
$$e_{ti} = v_a^T \tanh(W_a s_{t-1} + U_a h_i)$$
Burada $s_{t-1}$ Decoder’ın önceki durumu, $h_i$ Encoder’ın $i$. durumudur. Hesaplanan $e_{ti}$ skorları, Softmax fonksiyonu ile normalize edilerek $\alpha_{ti}$ ağırlıklarına dönüştürülür. Bu ağırlıklar, Encoder durumlarının ağırlıklı ortalamasını almak için kullanılır. Bu yöntem, bilgi darboğazını kırsa da, hizalama skorlarının hesaplanması hala yüksek maliyetliydi.1
Luong Dikkati (Multiplicative Attention):
Luong, 2015 yılında bu mekanizmayı basitleştirdi. Hizalama skorunu hesaplamak için bir sinir ağı yerine, vektörlerin Nokta Çarpımını (Dot Product) kullanmayı önerdi:
$$\text{score}(s_t, h_i) = s_t^T W h_i$$
Nokta çarpımı, iki vektör arasındaki benzerliği (açısal yakınlığı) ölçen en hızlı ve etkili yöntemdir. Bu yaklaşım, Transformer mimarisindeki “Scaled Dot-Product Attention”ın temelini oluşturmuştur. Luong ayrıca dikkatin sadece Encoder çıkışlarına değil, Decoder’ın kendi iç durumlarına da uygulanabileceği fikrini geliştirmiştir.2
1.3. Transformer Paradigması: “Attention Is All You Need”
2017 yılında Google Brain ekibi (Vaswani et al.), RNN ve CNN yapılarını tamamen terk ederek, sadece dikkat mekanizmasına dayalı Transformer mimarisini tanıttı. Bu makalenin başlığı (“Dikkat Her Şeydir”), radikal bir iddiayı temsil ediyordu: Sıralı işleme (recurrence) dil modelleme için bir zorunluluk değildir. Eğer her kelimenin diğer her kelimeyle olan ilişkisini aynı anda (paralel olarak) hesaplayabilirsek, hem uzun vadeli bağımlılıkları mükemmel bir şekilde modelleyebilir hem de modern donanımların paralel işlem kapasitesini sonuna kadar kullanabiliriz.
Transformer ile birlikte NLP’de işlem karmaşıklığı $O(N)$ sıralı adımdan, $O(1)$ sıralı adıma (ancak $O(N^2)$ hesaplama yüküne) dönüşmüştür. Bu değişim, bugün kullandığımız GPT, Claude ve Gemini gibi devasa modellerin eğitilmesini mümkün kılan temel mühendislik başarısıdır.1

2. Dikkat Mekanizmasının Matematiksel ve Teorik Temelleri
Transformer mimarisinin ve modern LLM’lerin kalbinde “Ölçeklendirilmiş Nokta Çarpım Dikkati” (Scaled Dot-Product Attention) yatar. Bu mekanizmayı derinlemesine anlamak için, vektör uzaylarında bilgi geri getirme (information retrieval) teorisine ve istatistiksel özelliklere bakmak gerekir.
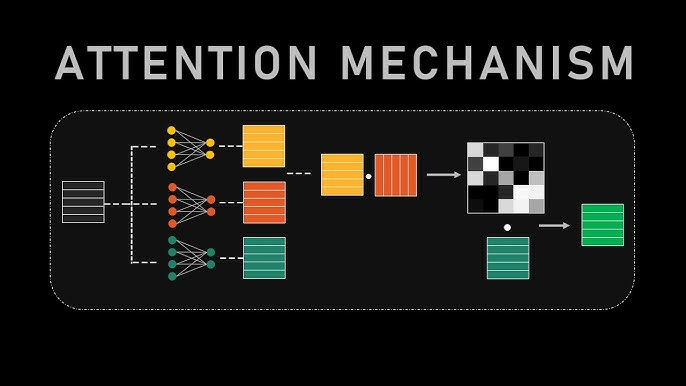
2.1. Vektör Uzayında Sorgulama: Query, Key ve Value
Dikkat mekanizması, özünde diferansiyellenebilir bir “Anahtar-Değer” (Key-Value) veritabanı sorgusudur. Sistemdeki her token (kelime/parça), üç farklı vektör temsiliyle ifade edilir. Bu vektörler, giriş gömme (embedding) vektörü $X$’in öğrenilebilir ağırlık matrisleri ($W^Q, W^K, W^V$) ile çarpılmasıyla elde edilir:
- Sorgu (Query – $Q$): $Q = X W^Q$. Bu vektör, tokenin “ne aradığını” temsil eder. Örneğin, bir özne konumundaki kelime, kendisine uygun bir yüklem arıyor olabilir.
- Anahtar (Key – $K$): $K = X W^K$. Bu vektör, tokenin “kim olduğunu” ve “ne içerdiğini” temsil eder. Bir indeks veya etiket gibi davranır. Sorgu vektörü ile eşleşmek için kullanılır.
- Değer (Value – $V$): $V = X W^V$. Bu vektör, tokenin “özünü” veya “içeriğini” temsil eder. Eğer anahtar ile sorgu eşleşirse, bu değer vektörü çıktıya aktarılacaktır.1
Analoji olarak; bir kütüphane veritabanında (Key), aradığınız konuyu (Query) tararsınız. En alakalı kitabın (Key ile Query eşleşmesi yüksek) içeriğini (Value) alırsınız. Ancak klasik veritabanından farklı olarak, dikkat mekanizması “yumuşak” (soft) bir seçim yapar; yani tek bir kitabı değil, alaka düzeyine göre tüm kitapların ağırlıklı bir karışımını getirir.
2.2. Ölçeklendirilmiş Nokta Çarpım Dikkati (Scaled Dot-Product Attention) Denklemi
Dikkat fonksiyonunun matematiksel ifadesi şöyledir:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
Bu denklemi bileşenlerine ayırarak analiz edelim:
2.2.1. Benzerlik Ölçümü ($QK^T$)
$Q$ matrisi ($N \times d_k$) ile $K$ matrisinin transpozu ($d_k \times N$) çarpılır. Sonuç ($N \times N$) boyutunda bir matristir. Bu matrisin $(i, j)$ hücresi, $i$. sorgu ile $j$. anahtar arasındaki nokta çarpımını (dot product) içerir. Nokta çarpımı, iki vektör arasındaki açının kosinüsü ile orantılıdır ve vektörler birbirine ne kadar benzerse (veya aynı yöne bakıyorsa) o kadar büyük bir değer alır. Bu aşamada elde edilen değerlere “ham dikkat skorları” (raw attention scores) veya “logitler” denir.1
2.2.2. Ölçekleme Faktörü ($\frac{1}{\sqrt{d_k}}$) ve Gradyan Kararlılığı
Formüldeki $\sqrt{d_k}$’ye bölme işlemi, bu mekanizmanın en kritik ancak en az anlaşılan parçalarından biridir. Neden ölçekleme yapıyoruz?
Bunu anlamak için istatistiksel bir varsayım yapalım: $Q$ ve $K$ vektörlerinin elemanlarının ortalaması 0, varyansı 1 olan bağımsız rastgele değişkenler olduğunu düşünelim ($q_i, k_i \sim \mathcal{N}(0, 1)$).
İki vektörün nokta çarpımı $q \cdot k = \sum_{i=1}^{d_k} q_i k_i$ şeklindedir.
Her bir $q_i k_i$ çarpımının ortalaması 0, varyansı 1’dir. $d_k$ adet terimin toplamının varyansı, varyansların toplamına eşittir.
Dolayısıyla, nokta çarpımının sonucu olan rastgele değişkenin varyansı $d_k$ olur (standart sapması $\sqrt{d_k}$).
Eğer $d_k$ büyükse (örneğin modern modellerde 128), nokta çarpım sonuçları çok geniş bir aralığa yayılır (örneğin -30 ile +30 arası). Softmax fonksiyonu ($e^x / \sum e^x$), büyük mutlak değerlere sahip girdiler için doygunluğa ulaşır (satures). Yani, en büyük değerin olasılığı 1’e, diğerlerininki 0’a çok yaklaşır.
Bu doygunluk bölgelerinde, Softmax fonksiyonunun türevi (gradyan) neredeyse sıfırdır. Geri yayılım (Backpropagation) sırasında, zincir kuralı gereği bu türevle çarpılan hata sinyali sönümlenir (“Vanishing Gradient”). Bu durum, modelin ağırlıklarını güncelleyememesine ve eğitimin durmasına neden olur.
$\sqrt{d_k}$ ile bölmek, nokta çarpım sonucunun varyansını tekrar 1’e indirger ($Var(X/c) = Var(X)/c^2$). Bu işlem, skorları Softmax’in türevinin yüksek olduğu, lineer ve hassas bölgeye çeker, böylece gradyan akışı sağlıklı bir şekilde devam eder.6
2.2.3. Olasılık Dağılımı (Softmax) ve Ağırlıklı Toplam
Softmax fonksiyonu, ham skorları bir olasılık dağılımına dönüştürür. Her satırdaki değerlerin toplamı 1 olur. Bu, $i$. kelimenin bağlamı oluşturulurken diğer kelimelerden “ne oranda” bilgi alınacağını belirler. Son olarak, bu ağırlıklar $V$ matrisi ile çarpılarak, ilgili bilgilerin (Values) ağırlıklı toplamı (Context Vector) elde edilir.1
3. Çok Kafalı Dikkat (Multi-Head Attention): Semantik Paralelizasyon
Tek bir dikkat mekanizması kullanmak, modelin kelimeler arasındaki ilişkiyi sadece tek bir boyutta (örneğin sadece gramer veya sadece anlam) kavramasına neden olabilir. Oysa dil çok katmanlıdır; “banka” kelimesi hem finansal bir kurumu hem de nehir kenarını ifade edebilir ve aynı cümlede hem özne hem de nesneyle ilişkili olabilir.
3.1. Temsil Alt Uzayları (Representation Subspaces)
Transformer mimarisi, bu sorunu Çok Kafalı Dikkat (Multi-Head Attention – MHA) ile çözer. Model boyutu $d_{model}$ (örn. 512), $h$ adet kafaya bölünür (örn. 8 kafa, her biri $d_k=64$). Her kafa, kendi bağımsız $W^Q, W^K, W^V$ matrislerine sahiptir.
$$\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1,…, \text{head}_h)W^O$$
$$\text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)$$
Bu yapı, modelin girdiyi farklı “alt uzaylara” (subspaces) izdüşürmesini sağlar. Her kafa, verinin farklı bir özelliğine odaklanmakta özgürdür. İşlemler paralel yapıldığı için, tek bir büyük dikkat matrisi hesaplamakla aynı maliyete sahiptir ancak çok daha zengin bir temsil gücü sunar.2
3.2. Kafaların Uzmanlaşması: Semantik vs. Sözdizimsel
Araştırmalar ve görselleştirme araçları (BERTViz vb.), eğitilmiş modellerdeki farklı kafaların farklı dilsel görevlerde uzmanlaştığını göstermiştir:
- Sözdizimsel Kafalar (Syntactic Heads): Bazı kafalar, cümlenin gramer yapısını takip eder. Örneğin, bir kafa sürekli olarak fiillerden nesnelere, başka bir kafa sıfatlardan niteledikleri isimlere dikkat (attention) yönlendirebilir.
- Konumsal Kafalar (Positional Heads): Bazı kafalar, içerikten bağımsız olarak sadece bir önceki veya bir sonraki token’a odaklanır. Bu, yerel bağlamın (n-gram benzeri yapıların) korunmasını sağlar.
- Semantik/Nadir Kelime Kafaları: Bazı kafalar, cümledeki nadir veya yüksek bilgi içeriğine sahip kelimelere (özel isimler, teknik terimler) odaklanır.
- Tümevarım Kafaları (Induction Heads): Özellikle LLM’lerin “In-Context Learning” (Bağlam İçi Öğrenme) yeteneğinin arkasındaki temel mekanizmadır. Bu kafalar, [A]… [A] ->? desenini yakalar. Yani, geçmişte A’dan sonra B’nin geldiğini görüp, şu anki A’dan sonra tekrar B’nin geleceğini tahmin etmeye odaklanırlar. İki katmanlı bir dikkat yapısı gerektiren bu mekanizma, modelin eğitim verisinde görmediği görevleri (few-shot learning) çalışma zamanında öğrenmesini sağlar.11
4. Konumsal Kodlamalar (Positional Encodings): Sırayı ve Mesafeyi Anlamlandırmak
Dikkat mekanizması doğası gereği “permütasyon değişmezdir” (permutation invariant). Matris çarpımı işlemi için $X_1$ ile $X_2$’nin yer değiştirmesi, sonucun sadece satırlarının yer değiştirmesi anlamına gelir; ancak dil modelleri için kelime sırası hayati önem taşır (“Ali Ayşe’yi gördü” ile “Ayşe Ali’yi gördü” tamamen farklıdır). Transformer’ın bu eksikliğini gidermek için Konumsal Kodlama kullanılır.
4.1. Mutlak Konumsal Kodlama (Sinusoidal APE)
“Attention Is All You Need” makalesinde önerilen orijinal yöntemdir. Token embeddinglerine, o tokenin mutlak sırasına ($pos$) bağlı olan sabit bir vektör eklenir (toplanır).
$$PE_{(pos, 2i)} = \sin(pos / 10000^{2i/d_{model}})$$
$$PE_{(pos, 2i+1)} = \cos(pos / 10000^{2i/d_{model}})$$
Bu fonksiyonların seçilme nedeni, trigonometrik dönüşüm formülleri sayesinde, modelin göreli pozisyonları ($pos+k$) lineer bir fonksiyon olarak öğrenebilme potansiyelidir. Ancak pratikte, bu yöntem eğitim sırasında görülen maksimum uzunluğun (context window) ötesine geçildiğinde (extrapolation) başarısız olur.14
4.2. Rotary Positional Embeddings (RoPE): Modern Standart
Günümüzde LLaMA, PaLM, Mistral gibi SOTA modellerin kullandığı yöntem RoPE’tur. RoPE, konumsal bilgiyi vektörlere eklemek yerine, vektörleri döndürerek (rotation) kodlar.
Matematiksel Türetim ve Karmaşık Sayılar
RoPE, $d$-boyutlu vektörü, $d/2$ adet 2-boyutlu alt vektöre böler. Her 2-boyutlu parçayı, karmaşık düzlemde bir sayı ($z = x + iy$) gibi düşünür. $m$ pozisyonundaki bir tokeni kodlamak için, bu vektör $m\theta$ açısı kadar döndürülür:
$$f(x, m) = x e^{im\theta}$$
Bu işlemin (Euler formülü kullanılarak) matris karşılığı şöyledir:
$$\begin{pmatrix} x’_1 \\ x’_2 \end{pmatrix} = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} x_1 \\ x_2 \end{pmatrix}$$
RoPE’un en büyük avantajı, iki vektör ($q$ pozisyon $m$, $k$ pozisyon $n$) arasındaki nokta çarpımının (dikkat skoru), mutlak pozisyonlardan bağımsız olarak sadece göreli mesafeye ($m-n$) bağlı olmasıdır:
$$\langle f(q, m), f(k, n) \rangle = \text{Re}(q e^{im\theta} (k e^{in\theta})^*) = \text{Re}(q k^* e^{i(m-n)\theta})$$
Bu özellik, modelin cümlenin neresinde olursa olsun kelimeler arası ilişkileri (örneğin “özne-yüklem” mesafesi) tutarlı bir şekilde tanımasını sağlar. RoPE, mutlak ve göreli kodlamanın avantajlarını birleştirir ve teorik olarak daha iyi uzunluk genellemesi sunar.16
4.3. ALiBi (Attention with Linear Biases)
ALiBi, konumsal kodlamayı tamamen ortadan kaldırır. Bunun yerine, dikkat skorlarına ($QK^T$), tokenler arasındaki mesafeyle orantılı statik bir ceza (bias) ekler.
$$\text{Attention score}_{i,j} = q_i \cdot k_j – m \cdot |i – j|$$
Burada $m$, her kafa için farklı belirlenen sabit bir eğim (slope) parametresidir.
Avantajı: ALiBi’nin en güçlü yanı ekstrapolasyon yeteneğidir. Örneğin, 1024 token ile eğitilen bir model, test sırasında 2048 veya daha fazla token ile çalıştırıldığında, Sinusoidal veya RoPE yöntemleri performans kaybederken (perplexity artarken), ALiBi kararlılığını korur. Çünkü model, “uzaktaki tokenlerin etkisi azalır” prensibini öğrenmiştir ve bu prensip her uzunlukta geçerlidir. BLOOM ve MPT modellerinde tercih edilmiştir.14
Karşılaştırma Tablosu:
| Yöntem | Tür | Matematiksel Temel | Avantaj | Dezavantaj | Kullanılan Modeller |
| Sinusoidal (APE) | Toplamsal (Additive) | Sinüs/Kosinüs frekansları | Basit uygulama | Ekstrapolasyon zayıf | Orijinal Transformer, BERT |
| RoPE | Çarpımsal (Multiplicative) | Karmaşık sayı rotasyonu | Göreli mesafe koruma, Yüksek performans | Hesaplama maliyeti az da olsa var | LLaMA, PaLM, GPT-NeoX |
| ALiBi | Bias Tabanlı | Lineer ceza fonksiyonu | Mükemmel ekstrapolasyon, Embedding yok | Uzun mesafeli ilişkileri aşırı cezalandırabilir | BLOOM, MPT |
5. Hesaplama Optimizasyonu ve Donanım Verimliliği
Transformer modellerinin en büyük zayıf noktası, dikkat mekanizmasının hesaplama (compute) ve bellek (memory) karmaşıklığının dizi uzunluğunun karesiyle ($O(N^2)$) artmasıdır. Bu durum, uzun metinlerin işlenmesini son derece maliyetli hale getirir.
5.1. FlashAttention: Donanım Farkındalı (IO-Aware) Algoritma
Standart PyTorch/TensorFlow dikkat uygulamaları, GPU bellek hiyerarşisini verimsiz kullanır.
GPU’larda iki ana bellek türü vardır:
- HBM (High Bandwidth Memory): Kapasitesi yüksek (40-80GB) ama yavaş.
- SRAM (Streaming Multiprocessor RAM): Kapasitesi çok düşük (192KB/SM) ama çok hızlı (HBM’den ~10-20 kat hızlı).
Standart algoritmada; $QK^T$ hesaplanıp HBM’e yazılır, sonra okunup Softmax uygulanır ve HBM’e yazılır, sonra okunup $V$ ile çarpılır. Ara matrisler ($N \times N$) devasa boyutlara ulaşır ve işlem Bellek Bant Genişliği (Memory Bandwidth) ile sınırlanır (Memory-Bound).
FlashAttention (v1, v2, v3), Stanford araştırmacıları (Tri Dao et al.) tarafından geliştirilen ve bu darboğazı aşan bir algoritmadır. Temel teknikleri şunlardır:
- Tiling (Döşeme/Bloklama): Büyük $Q, K, V$ matrislerini, SRAM kapasitesine sığacak küçük bloklara böler.
- Kernel Fusion: Dikkat hesabının tüm adımlarını (MatMul, Mask, Softmax, Dropout, MatMul) tek bir GPU çekirdeği (kernel) içinde, veriyi HBM’e hiç geri yazmadan (write-back) SRAM içinde tamamlar.
- Online Softmax: Softmax normalizasyonu için tüm satırın toplamına (payda) ihtiyaç vardır. FlashAttention, bloklar halinde ilerlerken “bölge maksimumunu” ve “kısmi toplamları” saklayarak Softmax’i dinamik olarak günceller ve kesin (exact) sonucu üretir.
- Recomputation (Yeniden Hesaplama): Geri yayılım (training/backward) sırasında, devasa ara matrisleri saklamak (activation checkpointing) yerine, onları SRAM içinde hızlıca tekrar hesaplar. Hesaplama (FLOPs) artsa da, yavaş HBM erişimi azaldığı için toplam süre kısalır.
Sonuç: FlashAttention, bellek kullanımını $O(N^2)$’den lineer seviyeye ($O(N)$) indirir ve işlem hızını 2-4 kat artırır. Bu, 32k, 100k gibi bağlam pencerelerinin önünü açan teknolojidir.23
5.2. KV Önbellekleme (KV Caching) ve Bellek Yönetimi
LLM’ler metin üretirken (inference) otoregresif çalışır; yani kelime kelime ilerler. 1000. kelimeyi üretirken, önceki 999 kelimenin $K$ ve $V$ vektörlerine ihtiyaç vardır. Bu vektörleri her adımda tekrar hesaplamak yerine GPU belleğinde saklarız (KV Cache).
Ancak uzun bağlamlarda KV Cache boyutu devasa hale gelir.
Örneğin: LLaMA-2 70B modeli, 16-bit hassasiyetle çalışırken, tek bir token için gereken KV bellek alanı:
$2 \times (\text{Layers}) \times (\text{Heads} \times \text{HeadDim}) \times 2 \text{ bytes}$.
Batch size 64 ve uzunluk 4096 olduğunda, sadece KV Cache yüzlerce GB yer kaplayabilir ve GPU belleğini (VRAM) doldurarak sistemi tıkar.29
5.3. Multi-Query (MQA) ve Grouped-Query Attention (GQA)
KV Cache darboğazını aşmak için mimari değişiklikler yapılmıştır:
- Multi-Head Attention (MHA): Standart yöntem. $h$ adet Query kafası için $h$ adet Key ve Value kafası vardır. Bellek tüketimi en yüksektir.
- Multi-Query Attention (MQA): Tüm Query kafaları, tek bir Key ve Value kafasını paylaşır. KV Cache boyutu $h$ kat küçülür. Çıkarım (inference) çok hızlanır, ancak modelin ifade gücü (kalitesi) azalabilir. (Google PaLM, Falcon).
- Grouped-Query Attention (GQA): MHA ve MQA arasında bir dengedir. Query kafaları gruplara ayrılır (örn. 8 grup). Her grup tek bir KV çiftini paylaşır. LLaMA-2 ve LLaMA-3 bu yöntemi kullanır. MQA kadar hızlıdır ancak MHA kadar kaliteli sonuçlar verir.
| Özellik | MHA (Multi-Head) | GQA (Grouped-Query) | MQA (Multi-Query) |
| KV Kafa Sayısı | $H$ (örn. 32) | $G$ (örn. 8) | 1 |
| KV Cache Boyutu | Büyük (Referans) | Orta (~1/4 Referans) | Çok Küçük (~1/32 Referans) |
| Model Kalitesi | En Yüksek | MHA’ya Çok Yakın | Hafif Düşüş Olası |
| Çıkarım Hızı | Yavaş | Hızlı | En Hızlı |
.32
6. Gelişmiş Fenomenler ve Yorumlanabilirlik
6.1. Attention Sinks (Dikkat Lavaboları) Fenomeni
MIT araştırmacıları, LLM’lerde ilginç bir davranış keşfetti: Model, cümlenin başındaki ilk tokene (genellikle <s> veya ilk kelime), anlamsal olarak önemsiz olsa bile aşırı yüksek dikkat skoru atamaktadır.
Bunun nedeni Softmax fonksiyonunun yapısıdır: $\sum P_i = 1$. Eğer o anki token (örn. 500. kelime) için geçmişte bakılacak “önemli” bir bilgi yoksa, Softmax’in ürettiği olasılık fazlalığının bir yere gitmesi gerekir. Model, ilk tokeni bir “çöp kutusu” (sink) olarak kullanmayı öğrenir.
StreamingLLM, bu bulguyu kullanarak “Sonsuz Bağlam” illüzyonu yaratır. Kayan pencere (Sliding Window) yöntemiyle son 1024 tokeni tutarken, pencere dışına çıkanları atar; ancak ilk 4 tokeni (Attention Sinks) asla atmaz. Bu sayede model, milyonlarca kelimelik bir konuşmayı, çökmeden ve “perplexity” artışı yaşamadan sürdürebilir.37
6.2. Dikkat Haritalarının Görselleştirilmesi (Interpretability)
Dikkat mekanizması, sinir ağlarının “kara kutu” yapısını bir nebze olsun aydınlatır. BERTViz gibi araçlar kullanılarak dikkat ağırlıkları görselleştirildiğinde, modelin nasıl düşündüğüne dair ipuçları elde edilir:
- Model bir zamiri (örn. “o”) işlerken, dikkat haritasında bu zamirin atıfta bulunduğu isme (örn. “Ayşe”) yoğun bir bağ oluştuğu görülür (Coreference Resolution).
- Çeviri modellerinde, kaynak dildeki kelimenin hedef dildeki karşılığına hizalandığı net bir şekilde izlenebilir (Alignment).
- Bu haritalar, modelin halüsinasyon gördüğü veya yanlış mantık kurduğu durumların tespitinde (debugging) kritik öneme sahiptir.40
7. Gelecek Perspektifi ve Sonuç
Dikkat mekanizması, yapay zeka tarihinde derin öğrenmeyi (Deep Learning) ölçeklenebilir kılan en önemli buluştur. RNN’lerin sıralı işleme kısıtlamasını kaldırarak, donanım gücünün (GPU) veriye (Big Data) tam kapasiteyle uygulanmasını sağlamıştır.
Ancak $O(N^2)$ karmaşıklığı, “fiziksel bir sınır” olarak karşımızda durmaktadır. 1 milyon tokenlik bir bağlam penceresi, trilyonlarca işlem demektir. FlashAttention, GQA ve RoPE gibi inovasyonlar bu sınırı zorlasa da, nihai çözüm belki de dikkatin kendisinin değiştirilmesinde yatmaktadır. Şu anda Lineer Dikkat (Linear Attention), State Space Models (SSM – Mamba) ve Ring Attention gibi yaklaşımlar, dikkat kalitesini korurken karmaşıklığı $O(N)$’e indirmeyi hedeflemektedir.
Alıntılanan çalışmalar
- Attention (machine learning) – Wikipedia, erişim tarihi Aralık 28, 2025, https://en.wikipedia.org/wiki/Attention_(machine_learning)
- From RNNs to Transformers: A Journey Through the Evolution of Attention Mechanisms in NLP – Medium, erişim tarihi Aralık 28, 2025, https://medium.com/@yacinebouaouni07/from-rnns-to-transformers-a-journey-through-the-evolution-of-attention-mechanisms-in-nlp-ef937e2c8d05
- arXiv:1706.03762v7 [cs.CL] 2 Aug 2023, erişim tarihi Aralık 28, 2025, https://arxiv.org/pdf/1706.03762
- An intuitive explanation of Self-Attention and Q, K, V Matrices in Transformers – Medium, erişim tarihi Aralık 28, 2025, https://medium.com/@prabhatsingh_59053/list-of-open-source-llms-8d22b34475cc
- [D] How does ‘self-attention’ work in transformer models? : r/MachineLearning – Reddit, erişim tarihi Aralık 28, 2025, https://www.reddit.com/r/MachineLearning/comments/16q8pwa/d_how_does_selfattention_work_in_transformer/
- erişim tarihi Aralık 28, 2025, https://medium.com/@jennifer.zzz/why-scaling-is-important-in-scaled-dot-product-attention-dca8d8cb9504#:~:text=Why%20the%20using%20sqrt(d_k,the%20variance%20back%20to%201.&text=the%20mean%20is%20still%200,the%20variance%20scaling%20upon%20multiplication.&text=Then%20the%20magnitude%20of%20the,t%20grow%20with%20their%20dimensions.
- Scaling Is All You Need: Understanding sqrt(dₖ) in Self-Attention – DEV Community, erişim tarihi Aralık 28, 2025, https://dev.to/samyak112/scaling-is-all-you-need-understanding-sqrtd-in-self-attention-29pk
- Understanding Scaling in Scaled Dot-Product Attention: Simple Math Insights – Medium, erişim tarihi Aralık 28, 2025, https://medium.com/@jennifer.zzz/why-scaling-is-important-in-scaled-dot-product-attention-dca8d8cb9504
- Purpose of sqrt(dim(k)) in Scaled dot product attention – DeepLearning.AI, erişim tarihi Aralık 28, 2025, https://community.deeplearning.ai/t/purpose-of-sqrt-dim-k-in-scaled-dot-product-attention/62880
- AI : Problem with Self-Attention? — Multi-Head Attention | by Shahwar Alam Naqvi | Medium, erişim tarihi Aralık 28, 2025, https://medium.com/@naqvishahwar120/ai-problem-with-self-attention-multi-head-attention-52bc4751bf6f
- Relation Extraction in Biomedical Texts Based on Multi-Head Attention Model With Syntactic Dependency Feature – NIH, erişim tarihi Aralık 28, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC9634522/
- Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned – ACL Anthology, erişim tarihi Aralık 28, 2025, https://aclanthology.org/P19-1580.pdf
- Identifying Semantic Induction Heads to Understand In-Context Learning – arXiv, erişim tarihi Aralık 28, 2025, https://arxiv.org/html/2402.13055v2
- Positional Embeddings in Transformers: A Math Guide to RoPE & ALiBi, erişim tarihi Aralık 28, 2025, https://towardsdatascience.com/positional-embeddings-in-transformers-a-math-guide-to-rope-alibi/
- Transformers Positional Encodings Explained | by João Lages – Towards AI, erişim tarihi Aralık 28, 2025, https://pub.towardsai.net/the-quest-to-have-endless-conversations-with-llama-and-chatgpt-%EF%B8%8F-81360b9b34b2
- Efficient Implementation of Rotary Positional Embedding – Yi Wang, erişim tarihi Aralık 28, 2025, https://wangkuiyi.github.io/rope.html
- Rotary Embeddings: A Relative Revolution | EleutherAI Blog, erişim tarihi Aralık 28, 2025, https://blog.eleuther.ai/rotary-embeddings/
- erişim tarihi Aralık 28, 2025, https://medium.com/@dewanshsinha71/rotary-positional-embedding-rope-7bc5afb92af9#:~:text=RoPE%20leverages%20the%20mathematical%20properties,i%C2%B7sin(%CE%B8).
- Rotary Positional Embedding (RoPE) Clearly Explained – Alan Dao’s personal blog, erişim tarihi Aralık 28, 2025, https://alandao.net/posts/rotary-positional-embedding-rope-clearly-explained/
- ALiBi: Attention with Linear Biases | ML & CV Consultant – Abhik Sarkar, erişim tarihi Aralık 28, 2025, https://www.abhik.xyz/concepts/attention/alibi
- ofirpress/attention_with_linear_biases: Code for the ALiBi method for transformer language models (ICLR 2022) – GitHub, erişim tarihi Aralık 28, 2025, https://github.com/ofirpress/attention_with_linear_biases
- Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation. – arXiv, erişim tarihi Aralık 28, 2025, https://arxiv.org/pdf/2108.12409
- FLASHATTENTION: Fast and Memory-Efficient Exact Attention with IO-Awareness, erişim tarihi Aralık 28, 2025, https://proceedings.neurips.cc/paper_files/paper/2022/file/67d57c32e20fd0a7a302cb81d36e40d5-Supplemental-Conference.pdf
- FLASHATTENTION: Fast and Memory-Efficient Exact Attention with IO-Awareness – OpenReview, erişim tarihi Aralık 28, 2025, https://openreview.net/pdf?id=H4DqfPSibmx
- FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision – PyTorch, erişim tarihi Aralık 28, 2025, https://pytorch.org/blog/flashattention-3/
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning – arXiv, erişim tarihi Aralık 28, 2025, https://arxiv.org/pdf/2307.08691
- Basic idea behind flash attention (V1) | Damek Davis’ Website, erişim tarihi Aralık 28, 2025, https://damek.github.io/random/basic-idea-behind-flash-attention/
- How Flash Attention works – Alvin Wan, erişim tarihi Aralık 28, 2025, https://alvinwan.com/how-flash-attention-works/
- KV cache offloading | LLM Inference Handbook – BentoML, erişim tarihi Aralık 28, 2025, https://bentoml.com/llm/inference-optimization/kv-cache-offloading
- LLM Inference Series: 4. KV caching, a deeper look | by Pierre Lienhart | Medium, erişim tarihi Aralık 28, 2025, https://medium.com/@plienhar/llm-inference-series-4-kv-caching-a-deeper-look-4ba9a77746c8
- Mastering LLM Techniques: Inference Optimization | NVIDIA Technical Blog, erişim tarihi Aralık 28, 2025, https://developer.nvidia.com/blog/mastering-llm-techniques-inference-optimization/
- Introduction to KV Cache Optimization Using Grouped Query Attention – PyImageSearch, erişim tarihi Aralık 28, 2025, https://pyimagesearch.com/2025/10/06/introduction-to-kv-cache-optimization-using-grouped-query-attention/
- Multi-head vs Multi-query vs Grouped-query attention | by Kantzuling – Medium, erişim tarihi Aralık 28, 2025, https://medium.com/@kantzuling0307/multi-head-vs-multi-query-vs-grouped-query-attention-6981715eb6ec
- arXiv:2305.13245v3 [cs.CL] 23 Dec 2023, erişim tarihi Aralık 28, 2025, https://arxiv.org/pdf/2305.13245
- Grouped Query Attention (GQA) vs. Multi Head Attention (MHA): LLM Inference Serving Acceleration – FriendliAI, erişim tarihi Aralık 28, 2025, https://friendli.ai/blog/gqa-vs-mha
- Grouped Query Attention (GQA) – GeeksforGeeks, erişim tarihi Aralık 28, 2025, https://www.geeksforgeeks.org/deep-learning/grouped-query-attention-gqa/
- Guangxuan Xiao¹, Yuandong Tian², Beidi Chen³, Song Han¹,4, Mike Lewis², erişim tarihi Aralık 28, 2025, https://iclr.cc/media/iclr-2024/Slides/18794.pdf
- [2309.17453] Efficient Streaming Language Models with Attention Sinks – arXiv, erişim tarihi Aralık 28, 2025, https://arxiv.org/abs/2309.17453
- Attention Sinks: Enabling Infinite-Length LLM Generation with StreamingLLM – Interactive | Michael Brenndoerfer, erişim tarihi Aralık 28, 2025, https://mbrenndoerfer.com/writing/attention-sinks-streamingllm-infinite-generation
- Explainable AI: Visualizing Attention in Transformers – Comet, erişim tarihi Aralık 28, 2025, https://www.comet.com/site/blog/explainable-ai-for-transformers/
- BertViz: Visualize Attention in NLP Models (BERT, GPT2, BART, etc.) – GitHub, erişim tarihi Aralık 28, 2025, https://github.com/jessevig/bertviz
- Visualize attention scores of LLMs with BertViz | by Gary Fan | Medium, erişim tarihi Aralık 28, 2025, https://medium.com/@GaryFr0sty/visualize-attention-scores-of-llms-with-bertviz-3deb94b455b3