

1. Giriş: İstatistiksel Olasılıktan Dijital Bilişe
Yapay zeka araştırmalarının mevcut durumu, insanlık tarihinin en karmaşık mühendislik ve matematiksel meydan okumalarından birini temsil etmektedir. Kullanıcının yönelttiği “sıfırdan bir dil modeli nasıl eğitilir?” sorusu, yüzeyde teknik bir reçete talebi gibi görünse de, özünde bilginin doğası, temsil teorisi ve zekanın mekanikleşmesi üzerine derin bir sorgulamadır.
Bu rapor, ham verinin (entropi) işlenebilir bilgiye (yapı) ve nihayetinde bir bilişsel modele (temsil) dönüşüm sürecini, akademik titizlik ve mühendislik detaylarıyla ele alacaktır. “Veri eğitilir” şeklindeki basitleştirici söylem, aslında arkadaki devasa matematiksel operasyonları, optimizasyon yüzeylerindeki gezintileri ve mimari tercihlerin yarattığı bilişsel sınırları gizleyen bir perdedir. Bu perdeyi kaldırarak, modern Büyük Dil Modellerinin (LLM) anatomisini, mevcut “sonraki token tahmini” (next-token prediction) paradigmasının sınırlarını ve bu sınırların ötesindeki nöromorfik ve sub-sembolik alternatifleri inceleyeceğiz.
Mevcut yapay zeka paradigması, büyük ölçüde Transformer mimarisine ve otoregresif öğrenme hedeflerine dayanmaktadır. Ancak, bu yaklaşımın insan beyninin çalışma prensipleriyle —özellikle enerji verimliliği, sürekli öğrenme ve hiyerarşik planlama açısından— ne kadar örtüştüğü tartışmalıdır. Raporda, sadece mevcut teknoloji değil, aynı zamanda Mamba (Durum Uzay Modelleri), JEPA (Birleşik Gömme Tahmin Mimarileri) ve Spiking Neural Networks (SNN) gibi geleceğin mimarileri de detaylandırılacaktır.
Şu yazı ilginizi Çekebilir Bu konu ile ilgili diğer yazılara buradan ulaşabilirsiniz:
2. Bölüm I: Veriden Temsile – Veri Hazırlama Boru Hattının (Pipeline) Mühendisliği
Bir dil modelinin inşası, mimari tasarımdan çok önce, verinin kürasyonu ile başlar. “Çöp girer, çöp çıkar” (Garbage In, Garbage Out) prensibi, LLM ölçeğinde “Gürültü girer, halüsinasyon çıkar” şeklinde revize edilebilir. Elinizdeki “bir sürü metin dosyası”, model için henüz ham maddedir ve bu maddenin rafine edilmesi, modelin zeka tavanını belirleyen en kritik faktördür.
2.1. Veri Alımı ve İlk Temizlik (Ingestion & Cleaning)
Veri hazırlığı, ham baytların anlamlı metin parçalarına dönüştürülmesiyle başlar. Bu aşamada karşılaşılan zorluklar, karakter kodlamalarındaki tutarsızlıklar ve metin olmayan gürültülerin ayıklanmasıdır.
2.1.1. Karakter Normalizasyonu ve Unicode Standartları
Metin dosyaları genellikle farklı kaynaklardan toplandığı için heterojen bir yapıdadır. İlk adım, karakter seviyesinde tutarlılığı sağlamaktır. Unicode standardı, aynı grafem (görsel karakter) için birden fazla kodlama sunabilir. Örneğin, “e” harfi üzerine aksan işareti koymak iki farklı yolla yapılabilir:
- Önceden Oluşturulmuş (Precomposed): Tek bir kod noktası kullanmak (örneğin, $U+00E9$ kodlu ‘é’).
- Birleştirilmiş (Decomposed): Temel harf ve aksan işaretini ayrı ayrı kodlamak (örneğin, $U+0065$ kodlu ‘e’ + $U+0301$ kodlu ‘´’).
Bir model için bu iki gösterim, tamamen farklı tokenler anlamına gelir. Bu durum, modelin aynı kelimeyi iki farklı şekilde öğrenmek zorunda kalmasına ve kelime dağarcığının (vocabulary) gereksiz yere şişmesine neden olur. Bu sorunu çözmek için NFKC (Normalization Form KC) algoritması uygulanır.1 NFKC, karakterleri uyumluluk (compatibility) ve kanonik birleşim (canonical composition) kurallarına göre standartlaştırır. Bu işlem, görsel olarak aynı olan tüm karakter dizilerinin, bayt seviyesinde de aynı olmasını garanti eder. Ayrıca, metin içindeki sıfır genişlikli boşluklar (zero-width spaces), yönlendirme işaretleri (Left-to-Right marks) ve bozuk UTF-8 sekansları bu aşamada temizlenir.
2.1.2. Heuristik Filtreleme ve Kalite Kontrolü
Veri setinin kalitesini artırmak için, RefinedWeb veya C4 gibi modern veri setlerinde kullanılan heuristik filtreler uygulanır.2 Bu filtreler şunları içerir:
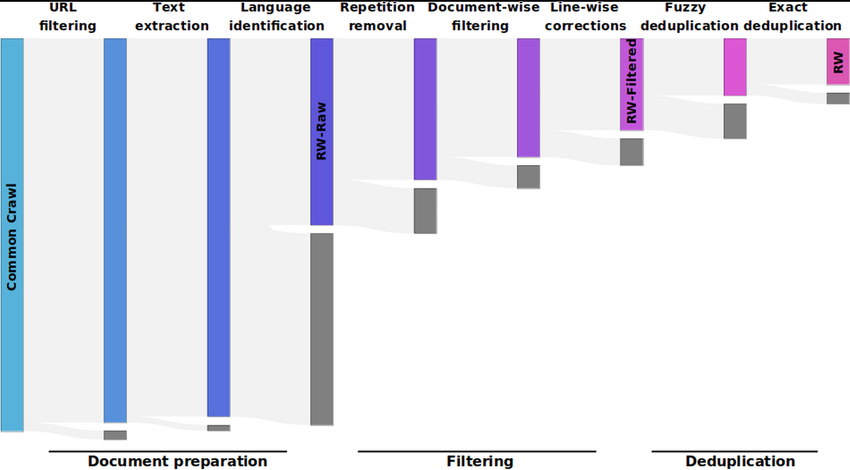
- Dil Tanımlama (Language Identification): fastText gibi sınıflandırıcılar kullanılarak, hedeflenen dil dışındaki dökümanlar ayıklanır.
- İstatistiksel Ayıklama: Bir dökümandaki sembol/kelime oranı, ortalama kelime uzunluğu veya cümle yapısı bozuklukları analiz edilir. Örneğin, kod parçacıkları veya log dosyaları genellikle doğal dilden farklı istatistiksel imzalara sahiptir ve bunlar eğitim verisinden çıkarılmalıdır.
2.2. Tekilleştirme (Deduplication): MinHash ve LSH
Büyük ölçekli veri setlerinde en kritik problemlerden biri veri tekrarıdır. Aynı metnin (örneğin viral bir haber, bir lisans metni veya spam içerik) binlerce kopyasının bulunması, modelin bu metinleri ezberlemesine (overfitting) ve eğitim verimliliğinin düşmesine neden olur. Milyarlarca dökümanı birebir karşılaştırmak ($O(N^2)$) hesaplama açısından mümkün değildir. Bu noktada, MinHash ve Locality Sensitive Hashing (LSH) algoritmaları devreye girer.2
2.2.1. MinHash Algoritmasının Matematiği
MinHash, Jaccard benzerliğini koruyan olasılıksal bir özetleme (hashing) yöntemidir.
- Shingling: Her döküman, $k$-shingles adı verilen (örneğin 5 kelimelik) kümeler dizisine dönüştürülür.
- Permütasyon ve İmza: Evrensel küme üzerinde $n$ adet rastgele permütasyon (hash fonksiyonu, $h_i$) tanımlanır. Her döküman ($S$) için, her permütasyondaki minimum hash değeri saklanır:
$$\text{sig}(S)_i = \min \{ h_i(x) \mid x \in S \}$$
Bu işlem sonucunda her döküman için $n$ uzunluğunda bir imza vektörü (MinHash signature) elde edilir. İstatistiksel olarak, iki kümenin MinHash değerlerinin eşit olma olasılığı, Jaccard benzerliklerine eşittir:
$$P(h_{\min}(S_1) = h_{\min}(S_2)) = J(S_1, S_2) = \frac{|S_1 \cap S_2|}{|S_1 \cup S_2|}$$
2.2.2. Locality Sensitive Hashing (LSH) ve Bantlama
MinHash imzaları oluşturulduktan sonra, benzer dökümanları bulmak için Bantlama (Banding) tekniği kullanılır. $n$ uzunluğundaki imza matrisi, her biri $r$ satırdan oluşan $b$ adet banda bölünür ($n = b \times r$).
- Her banttaki $r$ değer, bir hash tablosuna (bucket) atılır.
- Eğer iki döküman, en az bir bantta aynı bucket’a düşerse, bu dökümanlar “aday çift” (candidate pair) olarak işaretlenir.
- Bu yaklaşım, benzerlik eşiği $t \approx (1/b)^{1/r}$ olan dökümanları yüksek olasılıkla yakalar. Bu sayede, milyarlarca döküman arasında sadece potansiyel benzerler karşılaştırılarak işlem karmaşıklığı $O(N)$ seviyesine indirilir.5 RefinedWeb gibi veri setlerinde bu yöntemle %10-%15 oranında veri atılarak eğitim verimliliği artırılmaktadır.3
3. Bölüm II: Tokenizasyon – Metinden Sayıya Geçiş
Sinir ağları sembolik veriyi (kelimeler) doğrudan işleyemez; matematiksel işlemler yapabilmek için sayısal temsillere (vektörlere) ihtiyaç duyarlar. Tokenizasyon, metni atomik birimlere (token) bölme işlemidir. Geleneksel “boşluklara göre bölme” (word-level) yöntemi, kelime dağarcığının aşırı büyümesine (Curse of Dimensionality) ve nadir kelimelerin öğrenilememesine yol açar. Modern LLM’ler, Alt-Kelime (Subword) tokenizasyonu kullanır.
3.1. Byte-Pair Encoding (BPE) Algoritması
GPT ailesi (GPT-2, GPT-3, GPT-4) tarafından kullanılan standart yöntemdir. BPE, veri sıkıştırma algoritmalarından türetilmiştir ve deterministik bir birleştirme stratejisi izler.6
Algoritmanın Adımları:
- Hazırlık: Tüm kelimeler karakterlerine ayrılır ve sonlarına özel bir bitiş karakteri (ör. </w>) eklenir.
- İstatistik: Tüm korpus taranarak, yan yana gelen karakter çiftlerinin (bigram) frekansları sayılır.
- Birleştirme (Merge): En yüksek frekansa sahip çift (örneğin ‘e’ ve ‘s’ -> ‘es’) seçilir ve yeni bir token olarak kelime dağarcığına eklenir.
- Güncelleme: Korpus içindeki tüm ‘e’ ‘s’ dizilimleri ‘es’ sembolü ile değiştirilir.
- İterasyon: Hedeflenen kelime dağarcığı boyutuna (örneğin 50.000 token) ulaşılana kadar 2-4 adımları tekrarlanır.
BPE’nin gücü, sık kullanılan kelimeleri tek bir token olarak (örneğin “bilgisayar”), nadir kelimeleri ise alt parçalar halinde (örneğin “biliş-sel-leş-tir-me”) temsil edebilmesidir. Bu, modelin hiç görmediği kelimeleri (Out-of-Vocabulary – OOV) bile kök ve eklerine ayırarak anlamlandırmasını sağlar.8
3.2. SentencePiece ve Unigram Modeli
Google’ın T5, LLaMA ve Mistral gibi modellerinde tercih edilen yöntemdir. SentencePiece, metni kelimelere (boşluklara) bölmeden, ham bir bayt akışı olarak ele alır. Boşluk karakteri de (_ veya <0x20>) bir token olarak işlenir. Bu, tokenizasyonun tamamen tersine çevrilebilir (lossless reconstruction) olmasını sağlar.9
Unigram Dil Modeli (Unigram LM):
BPE’nin aksine, Unigram modeli deterministik birleştirme kuralları yerine olasılıksal bir yaklaşım kullanır.
- Büyük bir başlangıç kelime dağarcığı ile başlanır.
- Bir cümlenin ($X$) belirli bir token dizisi ($x_1, x_2, \dots, x_M$) olarak parçalanma olasılığı hesaplanır:
$$P(X) = \prod_{i=1}^{M} p(x_i)$$
Burada $p(x_i)$, token $x_i$’nin görülme olasılığıdır. - Expectation-Maximization (EM) algoritması kullanılarak, tüm korpusun log-olabilirliğini (log-likelihood) maksimize eden optimal token seti bulunur. Her iterasyonda, toplam olasılığa en az katkı sağlayan (loss fonksiyonunu en az etkileyen) tokenler kelime dağarcığından atılır (pruning).
Bu yöntem, dilin yapısına daha uygun ve esnek bir parçalama sağlar.10
4. Bölüm III: Mimari Tasarım – Transformer’ın Matematiği
Tokenizasyon işlemi tamamlandıktan sonra, veriler tamsayı dizilerine (Token ID’leri) dönüşür. Bu diziler, modern yapay zekanın omurgası olan Transformer mimarisine beslenir. “Sıfırdan eğitim” sürecinde, modelin her bir bileşeninin matematiksel gerekçesini anlamak kritiktir.
4.1. Gömme (Embedding) Uzayı ve Manifold Hipotezi
Her token ID, yüksek boyutlu bir vektör uzayına (örneğin $d_{model} = 4096$) yansıtılır. Bu işlem, basit bir tablo (Lookup Table) okumasıdır. Başlangıçta bu vektörler rastgele sayılardan oluşur (Gaussian initialization). Eğitim süresince, geri yayılım (backpropagation) algoritması bu vektörleri günceller.
Amaç, anlamsal olarak benzer kelimelerin (örneğin “kedi” ve “köpek”) vektör uzayında birbirine yakın, farklı kelimelerin (örneğin “kedi” ve “teori”) uzak konumlanmasını sağlamaktır. Bu, dilin yüksek boyutlu bir manifold üzerinde geometrik bir yapı olarak temsil edilmesidir.
4.2. Pozisyonel Kodlama: Rotary Positional Embeddings (RoPE)
Transformer mimarisi, veriyi paralel olarak işler (Permutation Invariant). Bu, modelin “Ali Ayşe’yi gördü” ile “Ayşe Ali’yi gördü” cümleleri arasındaki farkı anlamamasına neden olur. Sıra bilgisini modele enjekte etmek için Rotary Positional Embeddings (RoPE) kullanılır.12
Eski yöntemler (Sinusoidal Positional Encoding), pozisyon vektörünü kelime vektörüne topluyordu ($x + p$). RoPE ise vektörü uzayda döndürür.
$d$ boyutlu bir vektör $x$, $d/2$ adet alt-uzay (2D düzlem) olarak ele alınır. $m$ pozisyonundaki bir vektörün her alt parçası, şu açıyla döndürülür:
$$ \begin{pmatrix} x'{m,1} \ x'{m,2} \end{pmatrix} = \begin{pmatrix} \cos m\theta & -\sin m\theta \ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} x_{m,1} \ x_{m,2} \end{pmatrix} $$
Burada $\theta_i = 10000^{-2(i-1)/d}$ olarak tanımlanır.
RoPE’un matematiksel dehası, iki vektör arasındaki nokta çarpımının (dikkat skoru), mutlak pozisyonlara ($m, n$) değil, sadece aralarındaki göreli mesafeye ($m-n$) bağlı olmasını sağlamasıdır:
$$\langle f(x, m), f(y, n) \rangle = g(x, y, m-n)$$
Bu özellik (Relative Position Invariance), modelin eğitim sırasında gördüğünden daha uzun metinlere genelleme (extrapolation) yapabilmesini sağlayan temel mekanizmadır.14
4.3. Öz-Dikkat (Self-Attention): Bağlamın İnşası
Sizin “ahenk modeli” olarak tanımladığınız mekanizmanın kalbi burasıdır. Attention, bir tokenin bağlamdaki diğer tüm tokenlerle ilişkisini hesaplar.
Girdi vektörü ($X$), öğrenilebilir ağırlık matrisleri ($W_Q, W_K, W_V$) ile çarpılarak Sorgu (Query), Anahtar (Key) ve Değer (Value) vektörlerine dönüşür.
$$Q = XW_Q, \quad K = XW_K, \quad V = XW_V$$
Ölçekli Nokta Çarpım Dikkati (Scaled Dot-Product Attention)
Dikkat skorları şu formülle hesaplanır:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
Neden $\sqrt{d_k}$ ile bölüyoruz?
Vektör boyutu ($d_k$) büyüdükçe (örneğin 128), nokta çarpım ($QK^T$) sonuçlarının varyansı artar ve değerler büyür (örneğin 50, -100). Bu büyük değerler Softmax fonksiyonuna girdiğinde, fonksiyonun türevinin sıfıra çok yakın olduğu “doygunluk” (saturation) bölgelerine düşer.
$$\frac{\partial \text{softmax}(x)}{\partial x} \approx 0$$
Türevin sıfır olması, geri yayılım sırasında hatanın (gradient) aktarılamamasına (Vanishing Gradient) neden olur. $\sqrt{d_k}$ ile ölçekleme, varyansı 1’e sabitleyerek gradyan akışını sağlıklı tutar.16
Nedensel Maskeleme (Causal Masking):
Eğitim sırasında modelin gelecekteki kelimeleri görmemesi gerekir. Bu nedenle, dikkat matrisinin üst üçgeni $-\infty$ ile maskelenir. Softmax uygulandığında bu değerler 0 olur, böylece model sadece geçmişe ($t < current$) bakabilir.
4.4. Normalizasyon: RMSNorm
Derin ağlarda aktivasyonların stabil kalması için normalizasyon şarttır. Geleneksel LayerNorm yerine, modern LLM’lerde (LLaMA, Gemma) RMSNorm (Root Mean Square Norm) kullanılır. RMSNorm, ortalamayı (mean) hesaplamadan sadece varyansa (RMS) göre ölçekleme yapar.
$$\text{RMS}(x) = \sqrt{\frac{1}{n} \sum_{i=1}^{n} x_i^2 + \epsilon}$$
$$\bar{x}_i = \frac{x_i}{\text{RMS}(x)} \cdot g_i$$
Bu yöntem, hesaplama maliyetini düşürürken eğitimin stabilitesini korur. Modelin aktivasyonlarının büyüklüğünden (magnitude) ziyade yönüne (direction) odaklanmasını sağlar (Scale Invariance).18
5. Bölüm IV: Eğitim Döngüsü (Training Loop) ve Optimizasyon
Model mimarisi hazırlandıktan sonra, “veri eğitilir” aşaması başlar. Bu, parametre uzayında yapılan devasa bir optimizasyon problemidir.
5.1. İleri Yayılım (Forward Pass) ve Kayıp Fonksiyonu
Model, bir metin dizisini (context window) alır ve her adımda bir sonraki token için olasılık dağılımı (Logits) üretir. Hedef, modelin tahmin ettiği dağılım ($P$) ile gerçek veri ($Q$) arasındaki farkı minimize etmektir. Bunun için Cross-Entropy Loss (Çapraz Entropi Kaybı) kullanılır:
$$\mathcal{L} = – \sum_{x} Q(x) \log P(x)$$
LLM eğitiminde, gerçek veri “one-hot” olduğu için (tek bir doğru kelime var), formül şuna indirgenir:
$$\mathcal{L} = -\log(P(\text{doğru\_token}))$$
Bu fonksiyon, doğru token’a atanan olasılık 1’e yaklaştıkça 0’a, 0’a yaklaştıkça sonsuza gider.
5.2. Geri Yayılım (Backpropagation) ve Gradyan Hesabı
Kayıp değeri hesaplandıktan sonra, bu hatanın modeldeki her bir parametreye göre kısmi türevi ($\nabla_\theta \mathcal{L}$) hesaplanır. Bu işlem, zincir kuralının (Chain Rule) milyarlarca kez uygulanmasıdır. Modern GPU’larda bu işlem otomatik türev alma (autograd) kütüphaneleri (PyTorch, JAX) ile yapılır.
Bellek Yönetimi (Memory Efficient Training):
Kelime dağarcığı (Vocab Size) çok büyük olduğunda (örneğin 256.000), son katman (Logits) GPU belleğine sığmayabilir. Cut Cross-Entropy veya FlashAttention gibi teknikler, bu matrisleri bellekte tutmadan, bloklar halinde hesaplayarak bellek kullanımını (VRAM) minimize eder.20
5.3. Optimizasyon Algoritması: AdamW
Bulunan gradyanlar, parametreleri güncellemek için kullanılır. Standart SGD (Stokastik Gradyan İnişi) yerine, AdamW (Adaptive Moment Estimation with Decoupled Weight Decay) algoritması endüstri standardıdır.22
AdamW’nin Matematiği ve Önemi
Adam, her parametre için ayrı bir öğrenme hızı (learning rate) tutar.
- Momentum ($m_t$): Gradyanların hareketli ortalamasını tutar (Hızlanma).
- Varyans ($v_t$): Gradyanların karelerinin hareketli ortalamasını tutar (Frenleme/Ölçekleme).
Parametre güncelleme kuralı:
$$ \theta_{t+1} = \theta_t – \eta \left( \frac{\hat{m}_t}{\sqrt{\hat{v}_t} + \epsilon} + \lambda \theta_t \right) $$
Burada $\lambda \theta_t$ terimi, Ağırlık Çürümesi (Weight Decay) dir. AdamW’nin en önemli farkı, ağırlık çürümesini gradyan hesabından ayırarak (deoupled) doğrudan parametreye uygulamasıdır. Bu, L2 regularizasyonunun adaptif öğrenme hızlarıyla karışmasını önler ve modelin genelleme yeteneğini (test set performansı) dramatik şekilde artırır.24
6. Bölüm V: Paradigma Sorgusu – Sonraki Token Tahmini ve Ötesi
Kullanıcının “Tüm dil modelleri sonraki kelimeyi tahmin etmeye çalışan bir ahenk modeli aslında mı yani?” sorusu, yapay zekanın felsefi temelini sorgular.
Teknik olarak, evet. Modelin amaç fonksiyonu (objective function) sadece $P(w_t | w_{<t})$ olasılığını maksimize etmektir. Ancak, bu basit hedef, “ortaya çıkan özellikler” (emergent properties) yaratır.
6.1. Baskılama Yoluyla Öğrenme (Learning via Compression)
İlya Sutskever’in belirttiği gibi, “Veriyi mükemmel sıkıştırmak, veriyi üreten sistemi (dünya modelini) anlamayı gerektirir.” Bir sonraki kelimeyi doğru tahmin etmek için modelin sadece grameri değil, metindeki mantıksal akışı, olgusal gerçekleri ve neden-sonuç ilişkilerini içselleştirmesi gerekir.
6.2. Sembol Topraklama (Symbol Grounding)
Geleneksel görüş, LLM’lerin sembolleri (kelimeleri) fiziksel dünyadaki karşılıklarıyla eşleştirmediği, sadece semboller arası istatistiksel ilişkileri öğrendiği yönündedir (Stochastic Parrots hipotezi). Ancak 2024-2025 tarihli araştırmalar, Transformer’ların orta katmanlarında “Aggregate Heads” (Toplayıcı Kafalar) adı verilen özelleşmiş yapıların oluştuğunu göstermiştir.25
Bu kafalar, metindeki bağlamsal bilgileri (environmental tokens) toplar ve bunları dilsel tokenlere bağlar. Bu, mekanik bir “topraklama” (grounding) sürecidir. Yani model, eğitimi sırasında sadece kelime dizmiyor, içsel bir temsil uzayında (latent space) kavramsal haritalar oluşturuyor olabilir.25
7. Bölüm VI: Alternatif Mimariler – Akademi Ne Diyor?
Transformer mimarisi, “karesel karmaşıklık” ($O(N^2)$) sorunuyla malüldür. Metin uzadıkça işlem yükü karesel artar. Akademi ve endüstri, daha verimli ve “insani” alternatifler üzerinde çalışmaktadır.
7.1. Durum Uzay Modelleri (State Space Models – Mamba)
Mamba, Transformer’ın yerini almaya en güçlü adaydır. Temel farkı, hafıza mekanizmasıdır. Transformer tüm geçmişi saklarken, Mamba (tıpkı RNN’ler gibi) geçmişi sabit boyutlu bir “durum” (state) vektörüne sıkıştırır.
Seçici Mekanizma (Selection Mechanism):
Geleneksel Durum Uzay Modellerinde ($h_t = Ah_{t-1} + Bx_t$) matrisler sabittir. Mamba, bu matrisleri ($B, C, \Delta$) girdiye bağımlı (Input-Dependent) hale getirir.28
$$ B_t = \text{Linear}(x_t), \quad C_t = \text{Linear}(x_t), \quad \Delta_t = \text{Softplus}(\text{Parameter}(x_t)) $$
Bu sayede model, metni okurken “bunu unut, bunu sakla” diyerek dinamik bir hafıza yönetimi yapar. Bu özellik, “İçerik Tabanlı Seçicilik” (Content-based Selectivity) sağlar ve Transformer’ın dikkat mekanizmasına benzer bir odaklanma yeteneği kazandırır.
Paralel Tarama (Parallel Associative Scan):
Mamba’nın devrimi, yinelemeli (recurrent) bir süreci GPU üzerinde paralel çalıştırabilmesidir. Blelloch Scan algoritması kullanılarak, matris işlemlerinin birleşme (associativity) özelliğinden faydalanılır ve işlem $\log(N)$ sürede tamamlanır.30 Bu, hem eğitimde yüksek hız hem de çıkarımda (inference) sabit bellek kullanımı ($O(1)$ state) sağlar.
7.2. Joint Embedding Predictive Architectures (JEPA)
Meta AI Şefi Yann LeCun tarafından önerilen bu mimari, “üretken” (generative) yapay zekaya temelden bir itirazdır. LeCun’a göre, her pikseli veya kelimeyi tahmin etmek (reconstruction) verimsizdir ve gereksiz detaylarla (gürültü) uğraşmaktır.32
Dünya Modeli Yaklaşımı:
JEPA, girdinin bir kısmını ($x$) alır ve maskelenmiş kısmının ($y$) temsilini (embedding) tahmin etmeye çalışır. $y$’nin kendisini üretmez.
- Kodlayıcı (Encoder): Girdiyi soyut bir temsil uzayına taşır.
- Tahminci (Predictor): Temsil uzayında geleceği tahmin eder.
- Kayıp Fonksiyonu: Modelin “çökmesini” (her şeye aynı cevabı vermesini) önlemek için VICReg veya SimCLR gibi kontrastif olmayan (non-contrastive) kayıp fonksiyonları kullanılır.34
Bu yaklaşım, modelin sadece “önemli” bilgileri (soyut kavramları) öğrenmesini ve halüsinasyon görmeden (detay uydurmadan) planlama yapmasını hedefler.
7.3. Enerji Tabanlı Modeller (Energy-Based Models – EBM)
EBM’ler, veriyi olasılık dağılımı ($P(x)$) yerine bir enerji fonksiyonu ($E(x)$) ile modeller. Amaç, doğru verilere düşük enerji, yanlış verilere yüksek enerji atamaktır.
Difüzyon Modelleri (Diffusion Models): Metin üretiminde de kullanılmaya başlanan bu yöntem, metni soldan sağa (otoregresif) üretmek yerine, tamamen gürültüden (random noise) başlayıp iteratif olarak anlamlı bir cümleye dönüştürür (denoising). Bu, modele tüm cümleyi aynı anda görme ve planlama yeteneği kazandırır (Non-Autoregressive Generation).36
8. Bölüm VII: İnsan Beyni ve Sub-Sembolik Yapay Zeka
Kullanıcının “İnsan beyni kelime/sembol tabanlı bile değil, subsembolic” tespiti nörobilimsel olarak doğrudur. Dijital yapay zeka ile biyolojik zeka arasındaki uçurum tam da buradadır.
8.1. Sembolik vs. Sub-Sembolik İşlem
Klasik bilgisayarlar ve LLM’ler semboliktir (veya sembolik temsiller üzerine kuruludur). Beyin ise Sub-sembolik ve dağıtıktır. Beyinde “masa” kavramı için tek bir kayıt yoktur; bu kavram, milyonlarca nöronun aktivasyon deseninde (pattern) kodlanmıştır.
Hyperdimensional Computing (HDC) / Vektör Sembolik Mimariler:
Bu uçurumu kapatmak için çalışan HDC alanı, kavramları çok yüksek boyutlu (örneğin 10.000 bit) rastgele vektörlerle (Hypervectors) temsil eder.38
- Bağlama (Binding): İki vektör (ör. “Renk” ve “Kırmızı”) matematiksel olarak (ör. XOR veya Çarpma işlemiyle) birleştirilir.
- Süperpozisyon (Bundling): Birden fazla özellik (ör. “Renk:Kırmızı” + “Şekil:Yuvarlak”) toplanarak tek bir “Elma” vektörü oluşturulur.
Bu sistem, sembolik mantık işlemlerini (analoji, çıkarım) nöral (vektörel) bir altyapıda, gürültüye dayanıklı bir şekilde gerçekleştirebilir.
8.2. Spiking Neural Networks (SNN) ve Nöromorfik Donanım
Mevcut ANN’ler (Artificial Neural Networks), sürekli sayılarla (floating point) çalışır ve her nöron her adımda işlem yapar. Beyin ise Olay Tabanlıdır (Event-Driven). Nöronlar sadece voltaj belirli bir eşiği aşarsa “Spike” (dürtü) gönderir.
- Loihi 2 ve Lava: Intel’in geliştirdiği nöromorfik çipler, bu prensiple çalışır. Bilgi, spikeların zamanlamasında (Temporal Coding) saklıdır. Bu, enerji verimliliğini 1000 kat artırabilir.40
- Zorluk: Spike’lar türevsiz (non-differentiable) olduğu için, LLM’lerin belkemiği olan Backpropagation algoritması burada doğrudan çalışmaz. “Surrogate Gradient” yöntemleri ile bu engel aşılmaya çalışılmaktadır.
8.3. Öngörücü Kodlama (Predictive Coding) ve Aktif Çıkarım
Beynin öğrenme mekanizması muhtemelen Backpropagation değildir. Karl Friston’ın Öngörücü Kodlama (Predictive Coding) teorisi, beynin sürekli bir “tahmin makinesi” olduğunu savunur.42
- Hata Minimizasyonu: Beyin, aşağıdan (duyulardan) gelen veri ile yukarıdan (beyinden) gelen tahmini karşılaştırır. Sadece “fark” (Prediction Error) üst katmanlara iletilir.
- Aktif Çıkarım (Active Inference): Beyin hatayı azaltmak için sadece modelini güncellemez (öğrenme), aynı zamanda dünyayı değiştirmek için eyleme geçer (hareket). LLM’ler pasif gözlemcidir; beyin aktif bir ajandır. İnsan “düşüncesi”, bu döngünün duyusal veri olmadan (offline) simüle edilmesidir.
9. Sonuç ve Sentez
Sıfırdan bir dil modeli eğitmek, verinin entropisini azaltıp onu matematiksel bir manifolda yansıtma sanatıdır. Bu süreç; MinHash ile veriyi temizlemekten, BPE/Unigram ile atomlarına ayırmaya, RoPE ile uzayda döndürmekten, AdamW ile parametre uzayında en uygun noktayı aramaya kadar uzanan deterministik bir zincirdir.
Mevcut Transformer paradigması, “ahenk modeli” olmanın ötesine geçip, “baskılama yoluyla” bir dünya modeli öğrenme yeteneği göstermektedir. Ancak bu, biyolojik zekanın (enerji verimliliği, sürekli öğrenme, sub-sembolik işlem) sadece bir simülasyonudur. Gelecek; Mamba‘nın verimliliğinde, JEPA‘nın soyutlama gücünde ve Nöromorfik sistemlerin biyolojik gerçekliğinde yatmaktadır. Bu alanlar şu an akademide prototip aşamasını geçip, “ürünleşmeye yakın” evreye girmektedir.
Aşağıdaki tablolar, raporda tartışılan kavramların teknik özetini sunmaktadır.
Tablo 1: Tokenizasyon Algoritmalarının Karşılaştırılması
| Algoritma | Temel Prensip | Matematiksel Hedef | Kullanım Alanı | Avantaj/Dezavantaj |
| BPE | En sık tekrar eden çiftleri birleştirme (Merge Rules). | Veri sıkıştırma oranını artırma. | GPT-2, GPT-4, RoBERTa | Deterministik. Nadir kelimeleri iyi böler ama olasılık hesabı yapmaz. |
| Unigram LM | Olasılıksal modelleme. Gereksiz tokenleri budama (Pruning). | Veri setinin log-olabilirliğini ($\mathcal{L}$) maksimize etme. | T5, mBART, LLaMA (SentencePiece) | Olasılıksal. Bir kelime için birden fazla bölünme sunabilir (Regularizasyon imkanı). |
| WordPiece | Birleşimi, veri setinin olabilirliğindeki artışa göre seçme. | $P(xy) / (P(x)P(y))$ skorunu maksimize etme. | BERT, DistilBERT | BPE ve Unigram arasında bir denge. |
Tablo 2: Alternatif Mimariler ve İnsan Beyni İlişkisi
| Mimari | Temel Mekanizma | İnsan Beyni ile Benzerlik | Durum |
| Transformer | Dikkat (Attention) $O(N^2)$ | Kısa süreli çalışma belleği (Working Memory) simülasyonu. | Endüstri Standardı (LLaMA, GPT) |
| Mamba (SSM) | Seçici Durum (Selective State) $O(N)$ | Bilgiyi süzme ve unutma (Gating) mekanizması. | Yükselen Yıldız (Jamba, Mamba-2) |
| JEPA | Temsil Tahmini (Latent Prediction) | Detayları değil, anlamı/özü tahmin etme (Predictive Coding). | Araştırma (Meta AI – I-JEPA) |
| SNN | Spike (Dürtü) Tabanlı İşlem | Nöronal ateşleme, enerji verimliliği, asenkron işlem. | Prototip (Intel Loihi) |
Alıntılanan çalışmalar
- Decoding LLM Pipeline — Step 1: Input Processing & Tokenization – Towards AI, erişim tarihi Aralık 7, 2025, https://pub.towardsai.net/decoding-llm-pipeline-step-1-input-processing-tokenization-3e63b86ca2ac
- Blu-WERP (Web Extraction and Refinement Pipeline) A Scalable Pipeline for Preprocessing Large Language Model Datasets – arXiv, erişim tarihi Aralık 7, 2025, https://arxiv.org/html/2511.18054v1
- The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only – arXiv, erişim tarihi Aralık 7, 2025, https://arxiv.org/pdf/2306.01116
- Chapter 3 – Finding Similar Items – Stanford InfoLab, erişim tarihi Aralık 7, 2025, http://infolab.stanford.edu/~ullman/mmds/ch3n.pdf
- Minhash for compact set signatures – Locality sensitive hashing “BigData”, erişim tarihi Aralık 7, 2025, https://www.cs.cmu.edu/afs/cs/project/pscico-guyb/realworld/www/slidesS14/minhash.pdf
- Byte-pair encoding – Wikipedia, erişim tarihi Aralık 7, 2025, https://en.wikipedia.org/wiki/Byte-pair_encoding
- Byte-Pair Encoding: Subword-based tokenization algorithm – Medium, erişim tarihi Aralık 7, 2025, https://medium.com/data-science/byte-pair-encoding-subword-based-tokenization-algorithm-77828a70bee0
- merge – BPE multiple ways to encode a word – Stack Overflow, erişim tarihi Aralık 7, 2025, https://stackoverflow.com/questions/63263882/bpe-multiple-ways-to-encode-a-word
- SentencePiece Tokenizer Demystified – Towards Data Science, erişim tarihi Aralık 7, 2025, https://towardsdatascience.com/sentencepiece-tokenizer-demystified-d0a3aac19b15/
- Linguistic Laws Meet Protein Sequences: A Comparative Analysis of Subword Tokenization Methods – arXiv, erişim tarihi Aralık 7, 2025, https://arxiv.org/html/2411.17669v1
- A Rust SentencePiece implementation, erişim tarihi Aralık 7, 2025, https://guillaume-be.github.io/2020-05-30/sentence_piece
- Decoding Rotary Positional Embeddings (RoPE): The Secret Sauce for Smarter Transformers | by Sambit Kumar Barik | Medium, erişim tarihi Aralık 7, 2025, https://medium.com/@DataDry/decoding-rotary-positional-embeddings-rope-the-secret-sauce-for-smarter-transformers-193cbc01e4ed
- Rotary Embeddings: A Relative Revolution | EleutherAI Blog, erişim tarihi Aralık 7, 2025, https://blog.eleuther.ai/rotary-embeddings/
- Positional Embeddings in Transformers: A Math Guide to RoPE & ALiBi, erişim tarihi Aralık 7, 2025, https://towardsdatascience.com/positional-embeddings-in-transformers-a-math-guide-to-rope-alibi/
- Rethinking RoPE: A Mathematical Blueprint for N-dimensional Positional Embedding – arXiv, erişim tarihi Aralık 7, 2025, https://arxiv.org/abs/2504.06308
- Scaled Dot-Product Attention | ML & CV Consultant – Abhik Sarkar, erişim tarihi Aralık 7, 2025, https://www.abhik.xyz/concepts/attention/scaled-dot-product
- Why use a “square root” in the scaled dot product – Artificial Intelligence Stack Exchange, erişim tarihi Aralık 7, 2025, https://ai.stackexchange.com/questions/41861/why-use-a-square-root-in-the-scaled-dot-product
- Layer Normalization Explained – Lei Mao’s Log Book, erişim tarihi Aralık 7, 2025, https://leimao.github.io/blog/Layer-Normalization/
- LayerNorm and RMS Norm in Transformer Models – MachineLearningMastery.com, erişim tarihi Aralık 7, 2025, https://machinelearningmastery.com/layernorm-and-rms-norm-in-transformer-models/
- Cut Your Losses in Large-Vocabulary Language Models – arXiv, erişim tarihi Aralık 7, 2025, https://arxiv.org/html/2411.09009v1
- Mastering LLM Techniques: Training | NVIDIA Technical Blog, erişim tarihi Aralık 7, 2025, https://developer.nvidia.com/blog/mastering-llm-techniques-training/
- AdamW — PyTorch 2.9 documentation, erişim tarihi Aralık 7, 2025, https://docs.pytorch.org/docs/stable/generated/torch.optim.AdamW.html
- AdamW Optimizer in PyTorch Tutorial – DataCamp, erişim tarihi Aralık 7, 2025, https://www.datacamp.com/tutorial/adamw-optimizer-in-pytorch
- How to set AdamW’s weight decay as you scale model and dataset size – arXiv, erişim tarihi Aralık 7, 2025, https://arxiv.org/html/2405.13698v1
- Symbol Grounding in AI and Cognition – Emergent Mind, erişim tarihi Aralık 7, 2025, https://www.emergentmind.com/topics/symbol-grounding-problem
- The Mechanistic Emergence of Symbol Grounding in Language Models – arXiv, erişim tarihi Aralık 7, 2025, https://arxiv.org/html/2510.13796v1
- [Literature Review] The Mechanistic Emergence of Symbol Grounding in Language Models, erişim tarihi Aralık 7, 2025, https://www.themoonlight.io/en/review/the-mechanistic-emergence-of-symbol-grounding-in-language-models
- Mamba architecture : A Leap Forward in Sequence Modeling | by Puneet Hegde – Medium, erişim tarihi Aralık 7, 2025, https://medium.com/@puneetthegde22/mamba-architecture-a-leap-forward-in-sequence-modeling-370dfcbfe44a
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces – arXiv, erişim tarihi Aralık 7, 2025, https://arxiv.org/pdf/2312.00752
- A Visual Guide to Mamba and State Space Models – Maarten Grootendorst, erişim tarihi Aralık 7, 2025, https://www.maartengrootendorst.com/blog/mamba/
- Mamba’s Secret Weapon: The Mathematical Elegance of the Parallel Associative Scan | by DrSwarnenduAI | Data Science Collective – Medium, erişim tarihi Aralık 7, 2025, https://medium.com/data-science-collective/mambas-secret-weapon-the-mathematical-elegance-of-the-parallel-associative-scan-e9617f2644fa
- Joint Embedding Predictive Architectures – Emergent Mind, erişim tarihi Aralık 7, 2025, https://www.emergentmind.com/topics/joint-embedding-predictive-architectures-jepas
- Critical review of LeCun’s Introductory JEPA paper | Medium – Malcolm Lett, erişim tarihi Aralık 7, 2025, https://malcolmlett.medium.com/critical-review-of-lecuns-introductory-jepa-paper-fabe5783134e
- CNN-JEPA: Self-Supervised Pretraining Convolutional Neural Networks Using Joint Embedding Predictive Architecture – arXiv, erişim tarihi Aralık 7, 2025, https://arxiv.org/html/2408.07514v1
- The Anatomy of JEPA: The Architecture Behind embedded Predictive Representation Learning | by Tyler Frink | Medium, erişim tarihi Aralık 7, 2025, https://medium.com/@frinktyler1445/the-anatomy-of-jepa-the-architecture-behind-embedded-predictive-representation-learning-994bfa0bffe0
- Diffusion-NAT: Self-Prompting Discrete Diffusion for Non-Autoregressive Text Generation, erişim tarihi Aralık 7, 2025, https://aclanthology.org/2024.eacl-long.86/
- Energy-Based Diffusion Language Models for Text Generation – Research at NVIDIA, erişim tarihi Aralık 7, 2025, https://research.nvidia.com/publication/2025-01_energy-based-diffusion-language-models-text-generation
- Hyperdimensional computing – Wikipedia, erişim tarihi Aralık 7, 2025, https://en.wikipedia.org/wiki/Hyperdimensional_computing
- Hyperdimensional Computing: A New Match for Artificial Intelligence | by John Meléndez (馬強安 – 在臺灣) | Medium, erişim tarihi Aralık 7, 2025, https://medium.com/@John_Melendez/hyperdimensional-computing-a-new-match-for-artificial-intelligence-61d13302cc8c
- A Neuromorphic Transformer Architecture Enabling Hardware-Friendly Edge Computing, erişim tarihi Aralık 7, 2025, https://ieeexplore.ieee.org/document/10962199/
- Lava Software Framework — Lava documentation, erişim tarihi Aralık 7, 2025, https://lava-nc.org/
- The difference between LLMs and other kinds of predictive models, or humans, is … – Hacker News, erişim tarihi Aralık 7, 2025, https://news.ycombinator.com/item?id=41603319
- The Neural Correlates of Novelty and Variability in Human Decision-Making under an Active Inference Framework – eLife, erişim tarihi Aralık 7, 2025, https://elifesciences.org/reviewed-preprints/92892






8 thoughts on “Büyük Dil Modellerinin İnşası, Bilişsel Mimariler ve Sub-Sembolik Yapay Zeka”