İnsanlık tarihi boyunca “gerçeklik”, duyularımızla algıladığımız fiziksel dünyanın bir yansımasıydı. Ancak 21. yüzyılın ilk çeyreğinde, bu kabul geri dönülemez bir şekilde kırıldı. Bir videoda gördükleriniz, artık bir kameranın sensörüne çarpan fotonların kaydı değil; milyarlarca parametreye sahip bir yapay sinir ağının (ANN) olasılık hesapları sonucu ürettiği “halüsinasyonlar” olabilir. İnternette gördüğünüz bir videoda, ünlü bir politikacının asla söylemediği sözleri sarf ettiğini veya sevdiğiniz bir aktörün hiç oynamadığı bir film sahnesinde belirdiğini düşünün. Gözleriniz size bunun gerçek olduğunu söylüyor, ancak mantığınız reddediyor. İşte Deepfake, tam olarak bu bilişsel çelişkinin merkezinde yer alan teknolojidir.
“Deep Learning” (Derin Öğrenme) ve “Fake” (Sahte) kelimelerinin birleşiminden türetilen Deepfake, yapay zekanın (AI) en büyüleyici ve aynı zamanda en tehlikeli yeteneklerinden birini temsil eder. Bu sadece gelişmiş bir “Photoshop” değildir; bu, gerçekliğin matematiksel olarak yeniden üretimidir.
İlginizi Çekebilir: Tekinsiz Vadi Fenomeninin Psikolojik, Nörobiyolojik ve Teknolojik Bir İncelemesi
1. Deepfake Nedir ve Ne Değildir? Temel Tanım ve Kavramsal Çerçeve
Deepfake’i anlamak için önce ne olmadığını netleştirmek gerekir.
Ne Değildir?
- Geleneksel CGI (Computer Generated Imagery): Sanatçıların kare kare manuel müdahalelerini gerektirir ve oldukça maliyetlidir.
- Basit Yüz Değiştirme (Face Swap) Uygulamaları: Görüntüyü 2B bir düzlem gibi algılar ve maske gibi yapıştırır. Bu teknikler deterministiktir; her bir pikselin değeri fizik kuralları veya sanatçı kararlarıyla belirlenir.
Nedir?
Deepfake (Derin Kurgu), Derin Öğrenme algoritmalarını, özellikle de Üretken (Generative) modelleri kullanarak, mevcut bir medya içeriğindeki bir veya daha fazla unsuru, yapay olarak üretilmiş verilerle, insan algısının ayırt edemeyeceği bir gerçeklikte değiştirme veya yeniden oluşturma işlemidir. Sistem, bir yüzün geometrisini, ışıklandırmasını ve mikro mimiklerini öğrenerek, hedef videodaki kişinin yerine, kaynak kişinin yüzünü “sentetik” olarak oluşturur.
Bu teknoloji deterministik değil, stokastiktir (olasılıksal). CGI’da ışığın her yansımasını bir sanatçı veya fizik motoru hesaplar. Deepfake’te ise model, veri setinden öğrendiği “yüz kavramını” veya “ses dokusunu” istatistiksel bir dağılım üzerinden yeniden türetir.
2. Teknik Altyapı: Makinenin “Hayal Gücü” ve Zihni Nasıl Çalışır?

Deepfake teknolojisinin kalbinde, birbiriyle rekabet halinde gelişen üç ana mimari yatar: Autoencoders (Otokodlayıcılar), GANs (Çekişmeli Üretici Ağlar) ve son dönemde yükselen Diffusion (Difüzyon) Modelleri.
A. Autoencoder Mimarisi: Latent Uzayda Yolculuk
İlk nesil Deepfake’lerin (örneğin Reddit’te ortaya çıkan ilk örnekler ve DeepFaceLab gibi araçların) belkemiğidir. Sistem, veriyi sıkıştırıp tekrar açarak öğrenir.
- Encoder (Kodlayıcı – $E$): Girdi görüntüsünü ($x$) alır ve bunu “Latent Space” (Gizli Uzay – $z$) adı verilen, verinin en temel yapı taşlarını (göz aralığı, çene hattı, ışık açısı) barındıran düşük boyutlu bir vektöre sıkıştırır.
- z=E(x)
- z=E(x)
- Decoder (Kod Çözücü – $D$): Latent vektörü ($z$) alır ve orijinal görüntüyü yeniden oluşturmaya çalışır ($\hat{x}$).
- x^=D(z)
- x
- ^
- =D(z)
Manipülasyonun Matematiği:
Sistem eğitilirken, Kaynak Kişi (A) ve Hedef Kişi (B) için ortak bir Encoder kullanılır. Bu sayede Encoder, “insan yüzünün genel özelliklerini” öğrenir. Ancak her kişi için farklı Decoder’lar ($D_A$ ve $D_B$) eğitilir.
İşlem Akışı:
- Hedef Kişi B’nin yüzü ortak Encoder’a ($E$) verilir, yüzün geometrisi latent uzaya ($z_B$) çıkarılır.
- Bu $z_B$ verisi, B’nin değil, A’nın Decoder’ına ($D_A$) beslenir.
- Sonuç: B’nin mimiklerini ve ışıklandırmasını taşıyan, ancak A’nın yüz dokusuna ve hatlarına sahip hibrit bir görüntü.
B. GANs (Generative Adversarial Networks): Oyun Teorisi ile Üretim
Daha yüksek çözünürlük ve gerçekçilik için Çekişmeli Üretici Ağlar devreye girer. Ian Goodfellow tarafından geliştirilen bu yapı, bir “Minimax” oyununa dayanır.
- Generator (Üretici – $G$): Latent uzaydaki rastgele gürültüden ($z \sim p_z$) gerçekçi bir görüntü ($G(z)$) üretmeye çalışır. Amacı Discriminator’ı kandırmaktır.
- Discriminator (Ayırt Edici – $D$): Girdi olarak gelen verinin gerçek veri setinden mi ($x$) yoksa $G$ tarafından mı üretildiğini ayırt etmeye çalışır ($D(x)$).
Amaç fonksiyonu (Objective Function) şöyledir:
minGmaxDV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
min
G
max
D
V(D,G)=E
x∼p
data
(x)
[logD(x)]+E
z∼p
z
(z)
[log(1−D(G(z)))]
Bu rekabet (çekişme) sonucunda $G$, o kadar gerçekçi görüntüler üretmeye başlar ki, $D$ artık %50 şansla tahmin yürütmek zorunda kalır (yani ayırt edemez hale gelir). Bu noktaya Nash Dengesi denir. Özellikle StyleGAN mimarisi, görüntüdeki özellikleri (saç stili, yaş, cinsiyet) birbirinden ayrıştırarak (disentanglement) inanılmaz detay ve kontrol imkanı sunar.
C. Difüzyon Modelleri (Diffusion Models) ve Transformers: Devrimci Sıçrama
2022 sonrası Stable Diffusion, Sora, DALL-E 3 ile gelen sıçramanın mimarıdır. GAN’lardaki “mod çökmesi” (mode collapse) sorununu yaşamazlar ve daha stabil, çeşitliliği yüksek görüntüler üretirler.
- Forward Process (İleri Süreç): Bir görüntüye, tamamen rastgele bir Gaussian gürültüsüne dönüşene kadar kademeli olarak gürültü eklenir.
- Reverse Process (Ters Süreç): Bir sinir ağı (genellikle bir U-Net), bu gürültüyü adım adım kaldırarak (denoising) “hiçlikten” bir görüntü oluşturmayı öğrenir.
Bu modeller, özellikle Text-to-Video (Metinden Videoya) deepfake üretiminde devrim yaratmıştır. Artık bir kaynak videoya ihtiyaç duymadan, sadece “Papa’yı Balenciaga montla göster” gibi bir metin komutuyla fotogerçekçi çıktılar üretilebilmektedir.
3. Generative AI Devrimi ve Yeni Riskler: Ses, Dudak Senkronu ve Sıfır-Bilgi Erişim
2022 sonrası gelişmelerle Deepfake evrim geçirdi ve risk katmanları arttı.
- Voice Cloning (Ses Klonlama): VALL-E veya ElevenLabs gibi modeller, “Zero-Shot Learning” kullanır. Sadece 3 saniyelik bir ses örneğinden (acoustic prompt), konuşmacının tınısını (timbre), vurgusunu (prosody), şivesini ve hatta ortamdaki arka plan gürültüsünü kopyalayabilir. Bu sistemler, sesi bir dalga formu olarak değil, bir dizi “akustik token” olarak işler (GPT’nin kelimeleri işlemesi gibi).
- Lip-Sync (Dudak Senkronizasyonu): Wav2Lip gibi algoritmalar, bir videodaki kişinin dudak hareketlerini, tamamen farklı bir ses dosyasına milisaniyelik hassasiyetle yeniden çizer (inpainting). Bunu yaparken sadece ağzı değil, çene ve yanak kaslarını da sese uygun olarak deforme eder.
Neden Şimdi Daha Tehlikeli?
Eskiden güçlü GPU’lara ve derin Python/ML bilgisine ihtiyaç vardı. Bugün, Discord botları veya web arayüzleri sayesinde teknik bilgisi olmayan biri bile saniyeler içinde inandırıcı bir görsel+ses deepfake’i üretebilir. Demokratize olan bu teknoloji, asimetrik bir tehdit ortamı yaratmıştır.
4. Karanlık Taraf: Biyometrik ve Toplumsal Tehdit Vektörleri
Teknik hayranlık uyandırıcı olsa da, potansiyel sonuçları distopiktir.
- Dezenformasyon ve “Liar’s Dividend” (Yalancının Temettüsü): Seçim dönemlerinde politikacıların söylemediği sözleri söylemiş gibi gösteren videolar seçmeni manipüle edebilir. Daha sinsi olanı, sahte videoların varlığının, gerçek videoları inkar edilebilir kılmasıdır. Bir suçlu, aleyhindeki gerçek bir kanıt için “Bu bir deepfake” diyebilir.
- CEO Dolandırıcılığı (Vishing/CEO Fraud): Şirket yöneticilerinin sesleri klonlanarak, finans departmanlarına acil para transferi talimatları verilebilir. Bu senaryolar (örneğin 2019’da bir İngiliz enerji firmasında) halihazırda yaşanmaktadır. Geleneksel “Phishing”, yerini “Vishing”e (Voice Phishing) bırakmaktadır.
- Biyometrik Bypass (Injection Attacks): Finans ve güvenlik sistemleri kimlik doğrulama için “Liveness Detection” (Canlılık Tespiti) kullanır (örn: “Kafanı sağa çevir”). Gelişmiş Deepfake araçları, kameraya sanal bir sürücü (virtual driver) olarak girip, gerçek zamanlı yüz değiştirme yaparak bu güvenlik katmanlarını aşabilir.
- Rızasız Pornografi (Non-consensual Pornography): Deepfake teknolojisinin en yaygın ve zarar verici kullanım alanlarından biri, ünlülerin veya sıradan insanların yüzlerinin pornografik içeriklere monte edilmesidir. Bu, ciddi bir dijital şiddet ve mahremiyet ihlalidir.
5. Savunma Hattı: Adli Bilişim ve Deepfake Nasıl Tespit Edilir?
Kılıç ne kadar keskinleşirse, kalkan da o kadar güçlenmelidir. Adli bilişim uzmanları (Digital Forensics) ve araştırmacılar şu ileri düzey teknikleri kullanır: Bu konuyla ilgili Youtube’nin Deepfake üzerine aldığı algoritma önlem çalışması için bakabilirsiniz.
A. Biyolojik Sinyallerin Analizi
- rPPG (Remote Photoplethysmography): En sofistike yöntemlerden biridir. İnsan kalbi her attığında, yüzdeki damarlara kan pompalanır ve bu, gözle görülmeyen ancak kamerayla algılanabilen mikroskobik, periyodik renk değişimlerine neden olur. Normal bir videoda bu renk değişimleri (nabız), yüzün her bölgesinde senkronizedir. Deepfake’lerde bu “kan akışı” sinyali ya yoktur ya da tutarsızdır (spatially incoherent).
- Göz Kırpma Analizi: İlk dönem modelleri, eğitim verilerinde (fotoğraflarda) insanlar genelde gözleri açık olduğu için göz kırpma dinamiklerini (hızı, tam kapanması) öğrenemiyordu.
B. Frekans Alanı Analizi (Frequency Domain Analysis)
İnsan gözü görüntüyü uzamsal (spatial) olarak görür. Bilgisayarlar ise Hızlı Fourier Dönüşümü (FFT) ile frekans alanında inceleyebilir.
- Artefaktlar (Yapay İzler): GAN ve CNN tabanlı üretimler, “Upsampling” (çözünürlük yükseltme) aşamasında piksellerde matematiksel izler bırakır. Fourier spektrumunda bu izler, doğal fotoğraflarda olmayan anormal yüksek frekans yoğunlukları veya “checkerboard” (dama tahtası) desenleri olarak görülür.
C. Fiziksel Tutarlılık Analizi
- Kornea Yansımaları (Corneal Specular Highlights): Gözbebeği (kornea) son derece yansıtıcı bir yüzeydir. Bir kişinin iki gözündeki yansımalar, çevredeki ışık kaynaklarının konumuyla tutarlı olmalıdır. Modeller genellikle iki gözü bağımsız sentezlediği için, yansımalar uyumsuz olabilir veya sahne ışığıyla çelişebilir.
6. Gelecek ve Çözüm Arayışları: Kedi-Fare Oyunu ve C2PA
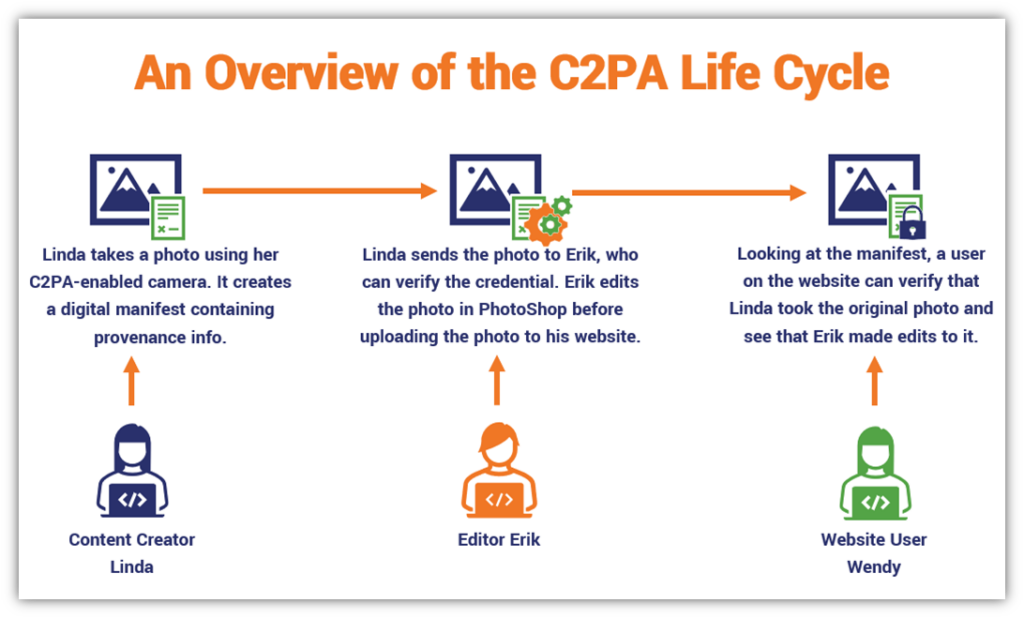
Generative AI, tespit algoritmalarından her zaman bir adım önde olma eğilimindedir. Bir tespit yöntemi yayınlandığında, geliştiriciler bu hatayı düzelten yeni bir model eğitirler (Adversarial Training). Bu nedenle nihai çözüm, sadece “tespit etmek” değil, “kaynağı doğrulamaktır”.
- C2PA (İçerik Kökeni ve Özgünlüğü İçin Koalisyon): Adobe, Microsoft, Intel ve diğer teknoloji devlerinin öncülüğünde geliştirilen bu açık standart, dijital içeriğe kriptografik bir “mühür” (provenance) vurur.
- Nasıl Çalışır? Kamera sensöründen, düzenleme yazılımına (Photoshop) ve son yayınlanan platforma kadar her adım, değiştirilemez bir dijital sertifika olarak dosyaya gömülür. Gelecekte tarayıcınızda bir resmin yanında “Bu görüntü Sony A7SIII ile 15.01.2023’te çekilmiş ve değiştirilmemiştir” veya “Bu görüntü Stable Diffusion 3 ile üretilmiştir” gibi doğrulanabilir ibareler göreceksiniz.
Sonuç: Şüphe Kaslarımızı Geliştirmek
Deepfake teknolojisi, atomun parçalanması gibidir; sinema (gençleştirme), eğitim (tarihi figürleri canlandırma) ve sanat için muazzam fırsatlar sunarken, aynı zamanda yıkıcı bir silaha dönüşebilir.
Artık “Gözlerimle gördüğüme inanırım” devri kapandı. En büyük savunma mekanizması, teknik okuryazarlığı artırmış, eleştirel düşünen bir insan bilincidir. Kaynağı sorgulamak, çapraz doğrulama yapmak ve dijital dünyadaki her içeriğe “Bu nasıl üretilmiş olabilir?” sorusuyla yaklaşmak, bu algoritmik illüzyon çağında ayakta kalmanın tek yoludur. Gözlerinize değil, verinin kökenine ve tutarlılığına inanın.